

")
Q1 – Match List 1 with List 2
List 1 | List 2 |
(a) BCNF iff | I. Every JD is implied by the candidate key |
(b) 5NF iff | II. All underlying domains contain scalar values only |
(c) 1NF iff | III. Every MVD is implied by the candidate key |
(d) 4NF iff | IV. Every FD is implied by the candidate key |
Choose the correct answer from the options given below:
(a)-III, (b)-II, (c)-I, (d)-IV
(a)-IV, (b)-I, (c)-II, (d)-III
(a)-II, (b)-III, (c)-IV, (d)-I
(a)-IV, (b)-I, (c)-III, (d)-II
(UGC NET DEC 2023)
Ans – (2)
Explanation – BCNF (Boyce-Codd Normal Form)
A relation is in BCNF if each functional dependency (FD) is a functional determinant of the obtained candidate key.
5NF (Fifth Normal Form)
A relation is in 5NF if each join dependency (JD) is the result of the candidate key.
1NF (First Normal Form)
A relation is already in 1NF if all the elementary domains store (individual) scalar attributes only (nonscalar and nested ones are not allowed).
4NF (Fourth Normal Form)
A relation is in 4NF if any multivalued dependency (MVD) is a function of the candidate key.
Q2 – Which one of the following are correct?
(a) Granularity is the size of data item in a database.
(b) Two operations in a schedule are said to be conflict if they belong to same transaction.
(c) Two schedulers are said to be conflict equivalent if the order of any two conflicting operations is the same in both schedules.
(d) Write operations which are performed without performing the write operation are known as Blind Writes.
Choose the correct answer from the options given below:
(a) and (b) only
(a), (b) and (c) only
(a), (b) and (d) only
(b) and (c) only
(UGC NET DEC 2023)
Ans – (2)
Explanation – (a) – Granularity refers to the size or level of detail in which data is processed, stored, or managed. It defines how small or large a unit of data is when being accessed or controlled.
In databases, granularity defines how much data is treated as a single unit for locking, concurrency control, and transactions.
Conflicting & Non-Conflicting Operations
Two operations from the same transaction always conflict. Whether they are read-read operations or read-write operations.
Two operations from the different transactions are conflicting if
- They operate on the same database element.
- One of the operations is write.
According to this –https://www.cs.emory.edu/~cheung/Courses/554/Syllabus/7-serializability/conflict.html
(b) – In the context of database transactions, two operations are considered conflicting if they are from the same transaction. Then the statement is correct.
(c) – Correct because conflict-equivalent schedules maintain the same order of conflicting operations, ensuring the same final result.
(d) – Write operations which are performed without performing the read operation are known as blind writes. But it says “without performing the write operation”, is absolutely wrong.
So, option 2 is correct.
Q3 – “CREATE TABLE T” in SQL is an example of:
Normalization
DML
DDL
Primary key
(UGC NET DEC 2023)
Ans – (3)
Explanation – Data Definition Language (DDL) is used to construct and maintain the structures of databases.
The DDL statements involve CREATE TABLE specifically meant to make a new table in a database.
Other DDL operators are ALTER, DROP, TRUNCATE, and RENAME.
Q4 – Which of the following is/are NOT CORRECT statement?
(a) The first record in each block of the data file is known as actor record.
(b) Dense index has index entries for every search key value in the data file.
(c) Searching is harder in the B+ tree than B- tree as the all external nodes linked to each other.
(d) In extensible hashing the size of directory is just an array of 2d-1 where d is global depth.
Choose the correct answer from the options given below:
(a), (b) and (c) only
(a), (c) and (d) only
(a), (b) and (d) only
(a), (b), (c) and (d) only
(UGC NET DEC 2023)
Ans – (2)
Explanation – (a) There is no concept of an “actor record” in file organization or indexing.
(b) An index in a database is similar to a listing of contents in a book since that enables one to quickly locate data without scanning the entire file.
There are two major types of indexes
Dense Index is having an entry for each and every search-key value in the data file.
This provides faster look-ups since a database record is indexed.
Sparse Index will have an entry for some records, and not all.
This will save space but it will take longer to find the data since additional searching inside the data blocks is required.
Hence the statement written is correct, but the question asks NOT CORRECT, so this is not the answer.
(c) A B+ tree features all keys being present only in the leaf nodes, which contain spans between them to speed up range queries; hence searching in a B+ tree is faster.
A B-tree features keys to exist in both internal nodes and leaf nodes which will complicate searching just a little bit. This is a NOT CORRECT statement.
(d) The size of the directory in extensible hashing is 2d, where d is the global depth. Hence, this statement is NOT CORRECT.
So, answer will be option number 2.
Question Number: 5.1 – 5.5
Question Label: Comprehension
(UGC NET DEC 2023)
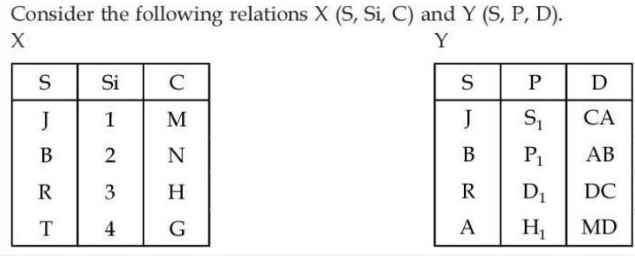
Q5.1 – Number of tuples by applying right outer join on relation X and Y is/are:
16
5
3
4
(UGC NET DEC 2023)
Ans – (3)
Explanation – Right outer join means all tuples from right table and matching tuples from left table.
S | Si | C | P | D |
J | 1 | M | S1 | CA |
B | 2 | N | P1 | AB |
R | 3 | H | D1 | DC |
A | Null | Null | H1 | MD |
There are 4 tuples in the result.
Q5.2 –
![]()
1
3
4
6
(UGC NET DEC 2023)
Ans – (3)
Explanation – The Left Outer Join is denoted by a left semi-circle symbol with a join sign (⟕).
Definition of Left Outer Join
A Left Outer Join collects all tuples from a first relation called “left” (X) and looks for correspondence in the second relation called “right” (Y) based on some common attribute S. If no matching tuple appears in Y, the missing field values receive NULL values.
- Join X and Y on common attribute S.
- Keep all tuples from the left.
- Fill P and D with NULLs in case Y does not match.
- J, B and R are in both relations, hence joining their preserved values.
- T is in X but not in Y, hence NULL in P, D as per the condition specified.
The final result contains 4 tuples and the answer is option 3.
Q5.3 – Which of the following join is used to get all the tuples of relation X and Y with Null values of corresponding missing values?
Left outer join
Right outer join
Natural join
Full outer join
(UGC NET DEC 2023)
Ans – (4)
Explanation – A full outer join (⟗) thus returns all matching tuples from both relations X and Y and if there is no matching tuple, NULL values are placed in any tuples for the attributes missing information.
Q5.4 – Number of tuples obtained by applying cartesian product over X and Y are:
16
12
04
32
(UGC NET DEC 2023)
Ans – (1)
Explanation – The number of tuples obtained by applying cartesian product over X and Y are –
X has 4 tuples and Y also has 4 tuples, so total tuples = 4 x 4 = 16 which is option 1.
Q5.5 –
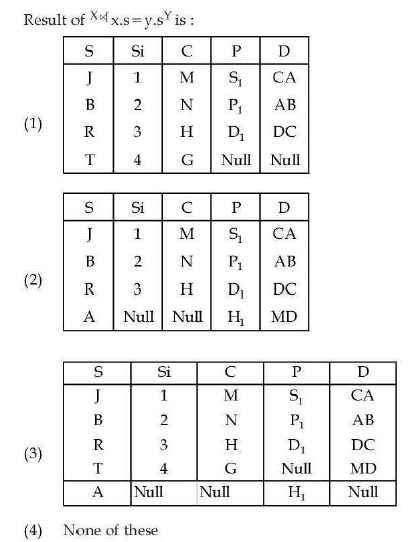
(UGC NET DEC 2023)
Ans – (2)
Explanation – A right outer join will return
- All tuples from the right relation (Y).
- Matching tuples from the left relation (X).
- If there is no match, NULL values are placed for missing attributes from X.
Apply the right outer join (X ⟖ Y)
The join condition is based on the S attribute (common key).
A right outer join guarantees that all tuples in Y will be in the result, even if they do not match with the left relation explicitly.
If a tuple in Y does not have a matching value in the left relation X, the missing columns from X will be placed with NULL values.
Hence the option will be 2.

