


“Trie,” pronounced “tri” or “tree,” is a data structure used to represent a group of strings. It supports fast pattern matching.
It can be visualized like a tree consist of edges and nodes and uses the prefixes of a string.
Prefix of a string “Tarun” is
‘T’
‘Ta’
‘Tar’
‘Taru’
‘Tarun’
Edward Fredkin was the first man who coined the term “trie” in the 1960s. Another name for trie is “digital tree,” “prefix tree,” or “radix tree.”
A data structure is used for storing and retrieving data. The word “trie” derives from the word “retrieval“.
Some of you may believe that hashing is the best data retrieval technique, but trie is a much faster algorithm than hashing.
.
Properties of trie
- It has the shape of multi-way tree.
- The root is always null.
- Each internal node stores one letter of the string.
- Each internal node is alphabetically ordered.
- Each leaf node stores a special symbol ‘$’ that is end of the string.
Types of tries
Standard trie
Compressed trie
Suffix trie
Standard Trie
Standard trie is a set of strings in which
- Each internal node has one letter of the string in alphabetical ordering.
- The path from the root to the distinct leaf represents a string.
Input – {BARK, BAT, NINE, NOT, NOTE}
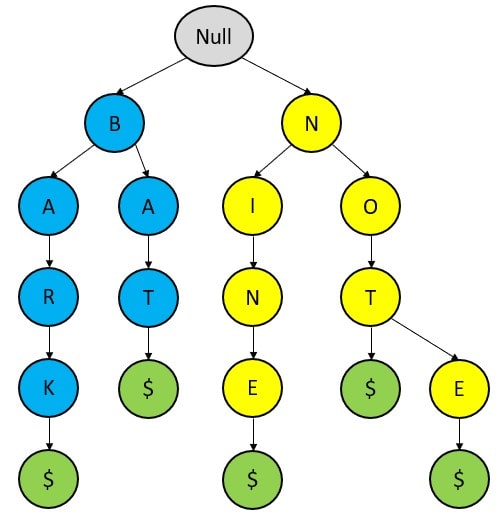
If a string is the prefix of another string, then we can add the $ sign after completion of it. {NOT, NOTE}. It is termed as ‘Handling Keys’.
.
Compressed Trie
Compressed trie is trie that is compressed with the redundant nodes.
Input – {BARK, BAT, NINE, NOT, NOTE}
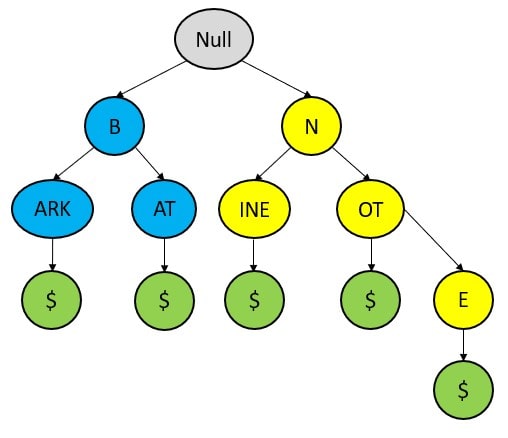
.
Suffix Trie
A suffix trie is just like a compressed trie, but it also contains all the unique suffixes of a string. It is a space-efficient data structure.
Input – {ZOOM}
Suffixes are – {ZOOM$, OOM$, OM$, M$, $}
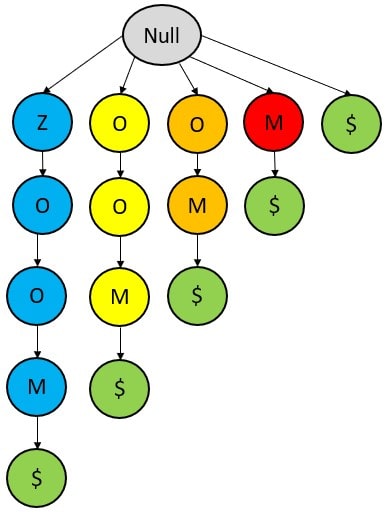
.

.
Operations on Trie
Searching
Insertion
Deletion
Searching
- If you want to search a string in a trie, then you have to start from the root node.
- There will be some internal nodes linking to the root node. The first letter of the string is to be searched in those internal nodes.
- If it is found then that node will be called reference node.
- Then we will search for second letter of the string linked to the reference node.
- While doing this, if we get the complete string, then we will call it a successful search.
- If not then we will see the next internal node which is linked to the root node and start searching the string with first letter.
- An unsuccessful search occurs when you traverse the full trie without finding the string.
Search – {NOTE$}

In searching,
- Time complexity is O(n) where n is the string we search.
- Space complexity is O(1).
Insertion
- If you want to insert a string in a trie, then you have to start from the root node.
- Search the string and if it is successful, then no need to insert duplicate string.
- If search is unsuccessful, then make a new node link to the root node and insert the first letter of the string.
- While creating a new node, check whether it is according to the dictionary or not.
- If string has k letters, create k nodes and insert the string’s letters as you move down.
- Finally, make a node for the special symbol $ that connects to the string’s last letter node.
Insert – {GOD$}

In insertion,
- Time complexity is O(n) where n is the string we insert.
- Space complexity is O(n) because we need ‘n’ more storage to insert.
Deletion
- If the string that is to be deleted is not found in the trie, then you can exit.
- If you found the string, delete it.
- One thing is to note be noted that if the string overlaps another string, then don’t delete the overlapping part.
Delete – {NOT$}
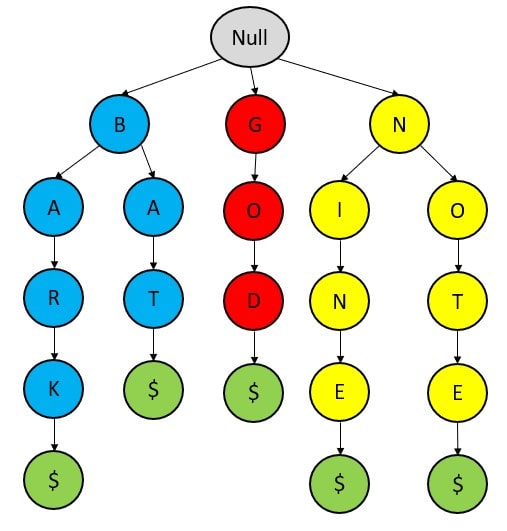
In deletion,
- Time complexity is O(n) where n is the string we delete.
- Space complexity is O(1).
Application
- Longest prefix match or String matching can be identified between many strings.
- Trie is a quick search engine that also serves as a spell checker for misspelt words.
- The Auto Complete tool suggests whole words when you input something in a chat, message, or search engine. This autocomplete feature is used by Google and WhatsApp. When we search “Cat” in Google, the autocomplete phrases “caterpillar,” “category,” and “catalyst” appear.
- Lexicographic sorting can be achieved by trie.
Advantages
- Fast insert and retrieve.
- There are alphabetically sorted strings like dictionary that can be used in many purposes.
- Faster than hashing.
Disadvantages
- More memory is used.
BOOKS



