


An Efficient Data Structure for Searching and Sorting
In the world of algorithms and data structures, skip lists stand out as an efficient and versatile data structure.
Skip-lists provide a balanced compromise between a sorted list and a linked list offering fast search, insertion, and deletion operations.
William Worthington Pugh Jr. is an American computer scientist who invented the skip list in 1989.
In this post, we will explore the concept of skip lists, their structure, and how they can be utilized in the design and analysis of algorithms.
.
What is a Skip List?
- A skip list is a probabilistic data structure that allows for efficient searching, insertion, and deletion operations in a sorted list.
- It consists of multiple layers or levels, with the bottom level representing the original sorted list.
- It skips many elements from the whole list, in one upper layer, which is why it is known as a skip list.
- The topmost layer acts as an “express lane” because it contains fewer elements than the layers below it.
- Each layer below has progressively more elements than the layer above it.
By utilizing these additional layers, skip lists can effectively “skip” over a large number of elements in a single step during searches, reducing the average time complexity.
The skip list achieves this by creating multiple levels of linked lists, where each element in a lower level has a pointer to the next occurrence of the same element in the level above. This structure allows for efficient traversal and search operations by taking advantage of the skip pointers.
.
Skip List Structure
The elements are arranged in the levels. At the bottom most level, there is a single linked list containing all the elements. As we move up the levels, some elements are “skipped” or bypassed, hence the name “skip list“. Each element on a particular level has pointers to the next element with a higher key value, effectively creating shortcuts to traverse the list more quickly.
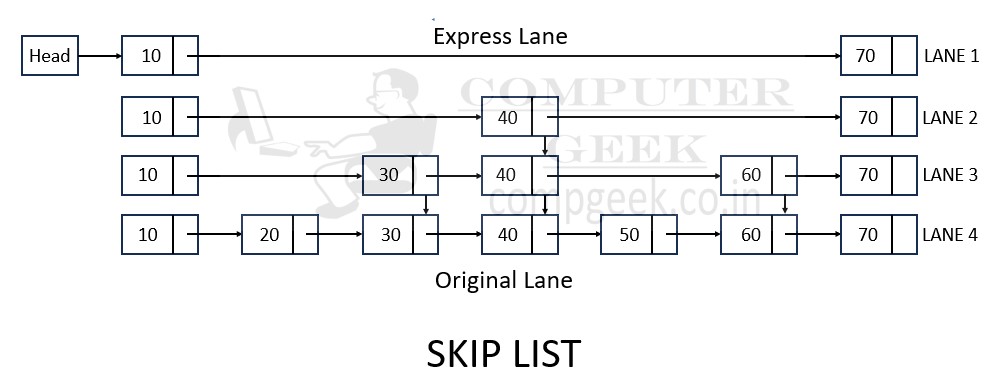
.
Searching
Searching in a skip list is similar to searching in a binary search tree but with the added advantage of faster average-case time complexity.
Starting from the top level, we start from the ‘HEAD’ and compare the target key with the current element. If the target key is greater, we move to the next element on the same level. If it is smaller, we move down to the next level and continue the search. This process continues until we either find the target element or reach the bottom level.
To search for the element 50 in the skip list you provided, we’ll start at the topmost layer and traverse down through the levels until we find the element or determine that it’s not present.
Let’s go step by step:
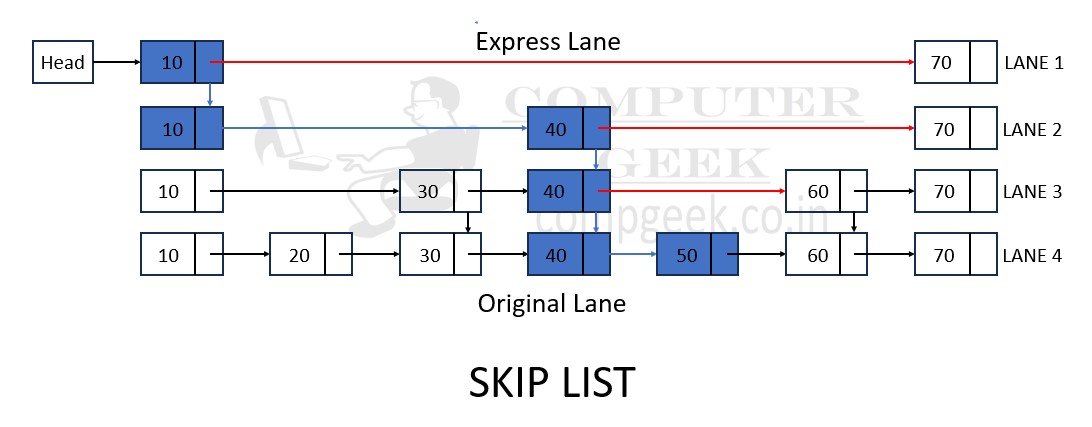
In figure 1, Start at the topmost layer (LANE 1), which contains fewer elements:
Move from Head to 10. (10 < 50)
Move from 10 to 70 through express lane. (70 > 50)
At this point, we reach the bottom layer (LANE 2) through 10.
Move from 10 to 40. (40 < 50)
Move from 40 to 70. (70 > 50)
At this point, we reach the bottom layer (LANE 3) through 40.
Move from 40 to 60. (60 > 50)
At this point, we reach the bottom layer (LANE 4) through 40.
Move from 40 to 50. (50 = 50)
Our search is Successful.
In this case, the search process required traversing two elements: 10 and 40, before reaching the element 50. The skip list allowed us to skip elements that were not necessary to examine (say 20 and 30), making the search faster compared to a linear search in a regular linked list.
Algorithm for Searching in a skip list
1. Start at the top-left corner of the skip list (the head node).
2. Move in a horizontal manner and compare the key of the node with the target key:
- If the current node’s key is equal to the target key, return the node or indicate that the key has been found.
- If the key of the current node is less than the target key, move horizontally to the next node on the same lane.
- If the key of the current node is greater than the target key, move to its previous node and vertically down to the next lane.
Repeat step 2 until one of the following conditions is met:
- You have reached the bottom level and there are no more nodes to explore. In this case, the target key is not present in the skip list means unsuccessful search.
- You have found a node with a key equal to the target key. In this case, the key has been found in the skip list, means successful search.
Before inserting and deleting a skip list, I would like to explain two concepts of a skip list.
Perfect Skip List
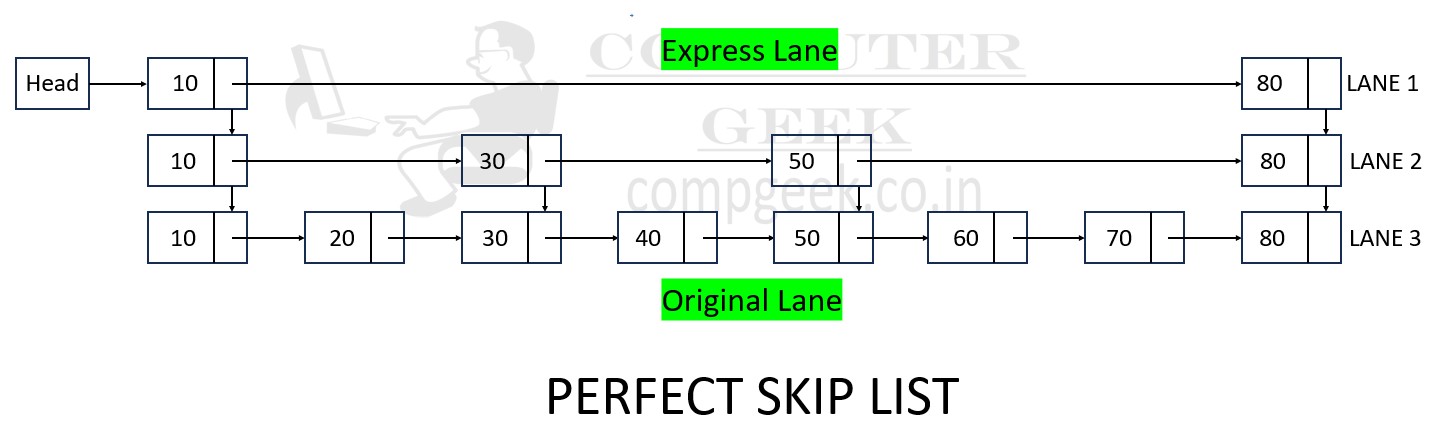
- A perfect skip list is a type of skip list that guarantees a specific structure.
- In a perfect skip list, each level has exactly half the number of nodes as the level below it.
- This results in a balanced and predictable structure.
- The topmost level contains just two nodes (One is starting node and second is last node), and each subsequent level doubles the number of nodes compared to the level below it.
- Inserting and deleting operation could not be done in perfect skip list. If we delete 50 from the perfect skip list, the diagram is completely messed up as after deleting LANE 3 has 7 elements and LANE 2 has only 3 elements.
Advantage of a perfect skip list
- It provides optimal search performance.
- The time complexity for search operations in a perfect skip list is O(log n), just like in a balanced binary search tree. However, maintaining the perfect structure of a skip list during insertions and deletions can be more complex and may require additional operations to rebalance the levels.
Randomized Skip List
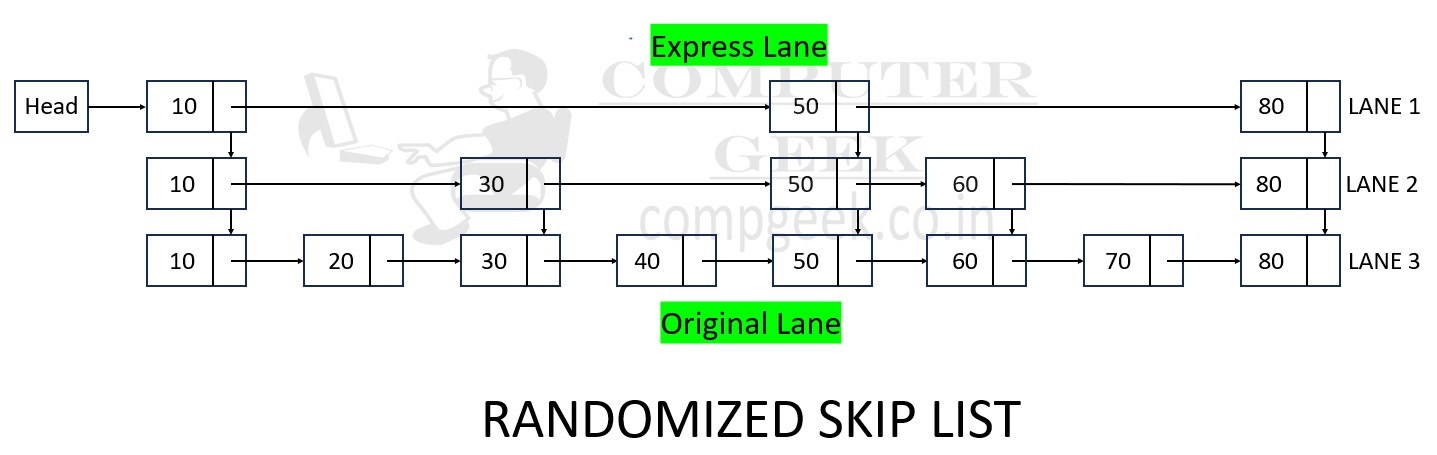
- A randomized skip list is a type of skip list that introduces randomness into the structure.
- The level of each node is determined randomly during the insertion process, following a certain probability distribution.
- This randomization creates an unpredictable structure that may vary between different instances of the skip list.
Insertion in Randomized Skip List
The coin randomization process is used to determine the level of each node during the insertion process.
Coin Randomization in Randomized Skip List
The coin flip is based on a probability distribution that determines the node level.
A simple explanation of the coin randomization technique follows:
1. Begin with a new node that must be added to the skip list.
2. Using a coin flip, determine the node’s level:
2.1 New node is placed in the original lane.
2.2 Toss a coin.
3. If head comes, then place new node in upper layer.
4. If tail comes, then stop the promotion in upper layers.
4.1 You have to toss the coin until you reach the maximum lane, if head comes again and again.
Deletion in Randomized Skip List
To maintain the skip list’s structure and order after deletion, we update the pointers at each level accordingly.
Algorithm for deletion in a Skip List
- Search the target key using algorithm of search.
- If a node with the target key is found:
- Remove the node from each level of the skip list by adjusting the pointers of the surrounding nodes:
- Update the pointers of the previous node and the next node to bypass the node to be deleted.
- Free the memory allocated to the node.
Repeat step 3 if there are duplicate nodes with the target key in the skip list.
Advantage of Randomized Skip list
This makes insertion operations faster and easier to implement. However, the randomness can result in slightly worse search performance compared to a perfect skip list, although the average-case time complexity is still O(log n).
Difference between Perfect and Randomized Skip list
BOOKS



