


Searching algorithm, refers to the process of finding a specific item or information within a given data structure or collection. It involves ‘systematically examining the elements or records’ in the data structure to determine whether the desired item is present and, if so, its location or other relevant details.
Searching is a fundamental operation in many applications, such as databases, information retrieval systems, web search engines, and more.
If you want to search a key or an element, then you can do it only in the data structure. Correct or good data structure is that data structure in which retrieval will be done in ‘less time’.
–
Array–
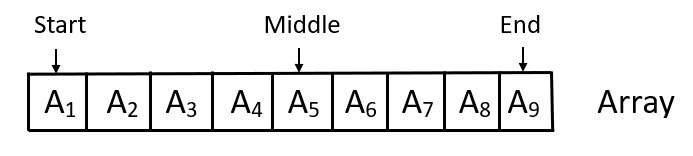
If you want to search in the array, then you can do it at the beginning, middle or end of the array in O(1) time.
–
Linked list–
If you want to search in a linked list, then there are three cases in which time complexity varies
(i) At the beginning, time complexity would be O(1)
(ii) In the middle, time complexity would be O(n/2) which is similar to O(n).
(iii) At the end, time complexity would be O(n).

Arrays provide fast access to elements using indices. Accessing an element by index has a time complexity of O(1).
But, inserting or deleting an element at the beginning or middle of an array requires shifting the subsequent elements, resulting in a time complexity of O(n).
However, accessing an element by index in a linked list has a time complexity of O(n) since you need to traverse the list from the beginning or end. But, inserting or deleting an element involves updating pointers, resulting in a time complexity of O(1) in the average case.
Also, linked lists also save memory as they only use the necessary space for each element, whereas arrays need contiguous memory allocation.
In the context of searching algorithms, the best case, average case, and worst case refer to different scenarios based on the number of comparisons required to find the target element. These cases help analyze the efficiency and performance of searching algorithms.
–
Best Case
The best case scenario represents the most favorable situation where the target element is found in the fewest number of comparisons. The best case time complexity is often denoted as Ω(1), indicating that the algorithm performs in constant time.
Average Case
The average case scenario represents the expected number of comparisons required to find the target element, considering all possible inputs.
Calculating the average case time complexity
Average = (1 + 2 + 3 + … + n)/n
Average means sum of all the searches (Best + Average + Average + … + Average + worst) divided by the comparisons occur.
Worst Case
The worst-case scenario represents the situation where the target element is found after the maximum number of comparisons. It represents the upper bound (O notation) on the performance of the searching algorithm.
The worst case often occurs when the target element is not present in the data structure or when it is located at the last position. The worst case time complexity is typically denoted as O(g(n)), where g(n) represents the upper bound function that characterizes the algorithm’s performance in the worst case.
.
Types of Searching
Linear search is a simple searching algorithm that sequentially checks each element in a list or array until the desired item is found or the end of the list is reached. It has a time complexity of O(n) in the worst case, where n is the number of elements in the list.
Sentinel linear search is a variation of linear search that improves its efficiency by reducing the number of comparisons. It involves placing a sentinel element (a special value) at the end of the list, allowing the search to terminate early when the target element is found. This technique eliminates the need for an explicit comparison with the end of the list, resulting in slightly faster performance.
Binary search is an efficient searching algorithm for sorted arrays. It follows a divide-and-conquer approach by repeatedly dividing the search space in half until the target element is found.
Binary search has a time complexity of O(log n) in the worst case, making it significantly faster than linear search for large datasets.
Meta binary search is an extension of binary search that incorporates multiple binary searches to improve efficiency. It is used when dealing with non-uniformly distributed data or when searching for multiple occurrences of the target element. By dividing the search space into smaller segments, meta binary search can reduce the number of comparisons and optimize the search process.
Ternary search is a divide-and-conquer searching algorithm similar to binary search but divides the search space into three parts instead of two. It is used when the search space is sorted and needs to be divided into three segments for comparison. Ternary search has a time complexity of O(log3n) and is advantageous when the data is evenly distributed.
Jump search is a searching algorithm suitable for sorted arrays or lists. It involves repeatedly jumping or skipping ahead by a fixed number of steps to quickly reach a range where the target element might be located. Once this range is determined, linear search is performed within that range. Jump search has a time complexity of O(√n) in the worst case.
Interpolation Search
Interpolation search is an algorithm for searching in sorted arrays, particularly when the data is uniformly distributed. It estimates the position of the target element by using interpolation formulae and adjusts the search space accordingly. Interpolation search can achieve better time complexity than binary search in certain scenarios.
Exponential Search
Exponential search is a searching algorithm that combines binary search and linear search. It begins with a small range and exponentially increases the search range until an element greater than the target is found. It then performs binary search within the previous range. Exponential search is particularly useful when the target element is closer to the beginning of the array.
Fibonacci search is a searching algorithm that uses the Fibonacci sequence to divide the search space into smaller segments. It follows a similar approach to binary search but divides the array into Fibonacci numbers to determine the next comparison point. Fibonacci search has a time complexity of O(log n) and is beneficial when the search space is large.
The Ubiquitous Binary Search refers to the application of binary search in various problem-solving scenarios. Binary search is a versatile algorithm used in a wide range of applications, such as finding a specific element, determining an insertion point, or solving optimization problems. Its efficiency and simplicity make it one of the most widely used searching techniques.
Randomized search refers to a technique where we explore different options randomly to find a solution to a problem. Instead of following a specific order or pattern, we make random choices and evaluate their effectiveness.
Imagine you are searching for a specific book in a library. Instead of going through the books in a systematic way, you randomly pick a shelf, select a book from that shelf, and check if it’s the one you’re looking for. If not, you repeat the process by randomly choosing another shelf and book until you find the desired book.
One more important point is that, rather than focusing on best case, average case, and worst case scenarios as traditionally done in deterministic algorithms, the time complexity is expressed in terms of the expected number of operations or comparisons required for a given input size.
Let’s explain the types of searching one by one in the next posts.
BOOKS



