


Introduction
.
The Longest Common Subsequence (LCS) algorithm is a popular method in computer science used to find the longest subsequence common to two sequences (such as strings).
A subsequence is a sequence that appears in the same order but not necessarily consecutively.
The LCS algorithm uses a dynamic programming approach, which breaks down the problem into smaller subproblems, solves each subproblem once, and stores the results for future reference.
This method significantly reduces the computational effort compared to naive approaches and recursion approaches that might involve excessive repetition of calculations.
.
History
The study of string matching and sequence alignment problems dates back to the early days of computer science. Researchers were interested in finding efficient ways to compare and align sequences, which has applications in text processing, DNA and RNA sequence analysis, and other areas.
The concept of dynamic programming, which is crucial for efficiently solving the LCS problem, was introduced by Richard Bellman in the 1950s. Dynamic programming is a method for solving complex problems by breaking them down into simpler subproblems and storing the results of these subproblems to avoid redundant calculations.
.
How it can be solved
There are several methods for solving LCS problem
- Naïve Method
- Recursion Method
- Dynamic Programming
.
1. Naïve Method –
- Generate all possible sub-sequences for both sequences.
- Compare each subsequence of the first sequence with each subsequence of the second sequence.
- Identify the longest common subsequence.
Example –
Sequence 1 = ABCD
Sequence 2 = ACDB
From Naïve method –
Sequence 1 – all possible sub-sequences
A, B, C, D, AB, AC, AD, BC, BD, CD, ABC, ABD, ACD, BCD, ABCD
Sequence 2 – all possible sub-sequences
A, C, D, B, AC, AD, AB, CD, CB, DB, ACD, ACB, ADB, CDB, ACDB
.
Compare each sub-sequence of first sting to the second string
‘A’, ‘B’, ‘C’, ‘D’, ‘AB’, ‘AC’, ‘AD’, ‘CD’, ‘ACD’
.
Longest common sub-sequence is ‘ACD’
.
Time Complexity of brute force algorithm.
For a sequence of length n, there are 2n possible sub-sequences.
Comparing all sub-sequences of two sequences of length m and n takes O(2m * 2n) time.
Space Complexity of brute force algorithm is O(2m * 2n) to store all sub-sequences.
.
2. Recursion Method –
- Compare the last characters of both sequences.
- If they match, the character is part of the LCS.
- If they do not match, recursively find the LCS in two scenarios: excluding the last character of the first sequence and excluding the last character of the second sequence.
- The result is the longer LCS found in the two scenarios.
Example –
Index | 0 | 1 | 2 | 3 |
Sequence 1 | A | B | C | D |
Sequence 2 | A | C | D | B |
From Recursion method –
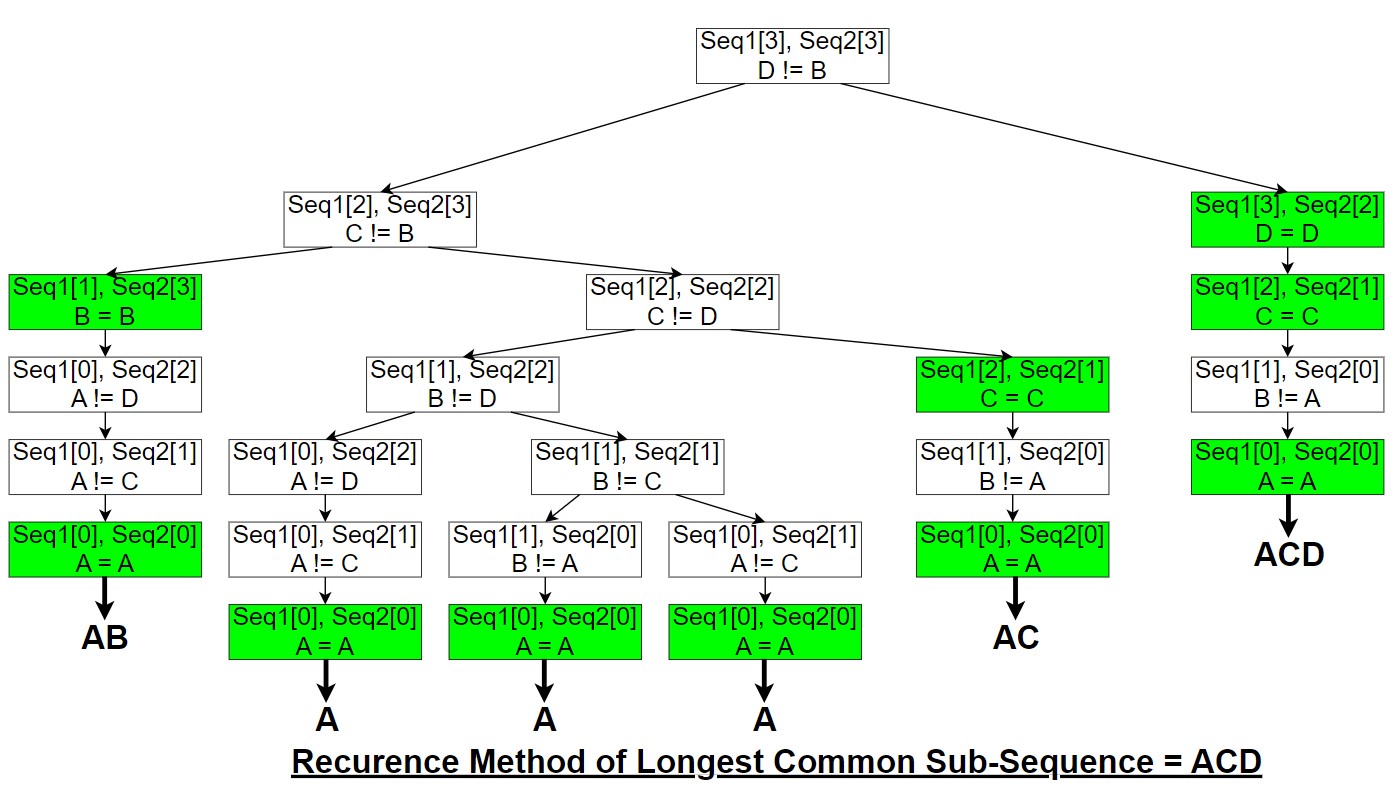
.
Using the recursion method, we find that the LCS length of Sequence 1 = “ABCD” and Sequence 2 = “ACDB” is 3.
The actual LCS can be determined by tracking the characters included in the matching cases, which in this example would be “ACD”.
Time Complexity of Recursion Method – O(2min(m,n)), because for each character pair, we have two choices (exclude one character from either sequence), leading to a total of 2min(m,n) combinations in the worst case. But in the recursion method, it only explores relevant subproblems rather than generating all sub-sequences, so therefore its time complexity reduces to min(m,n)2.
Space Complexity of Recursion Method – O(n), due to the call stack depth.
- Dynamic Programming Algorithm –
The dynamic programming approach for solving the Longest Common Subsequence (LCS) problem is efficient and avoids redundant calculations by storing intermediate results.
This method uses a table to keep track of the lengths of LCS for different substrings of the given sequences.
.
Algorithm for LCS using Dynamic Programming (dp)
- Input
- Two sequences seq1 of length m.
- Two sequences seq2 of length n.
- Create a 2D Table
- Create a 2D table dp with dimensions (m+1) x (n+1).
- Initialize all elements of dp to 0.
- Fill the Table
- Loop through each character in seq1 and seq2.
- If characters match, update the dp table with the value from the diagonal cell plus one.
- If characters do not match, update the dp table with the maximum value from the cell to the left or the cell above.
- Retrieve the Result:
- The value in dp[m][n] contains the length of the LCS.
Example –
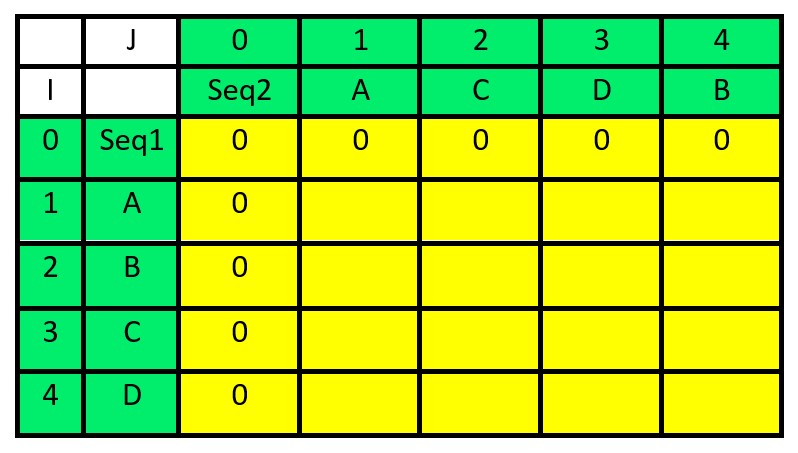
Let’s consider seq1 = “ABCD” and seq2 = “ACDB”
Create and initialize the table
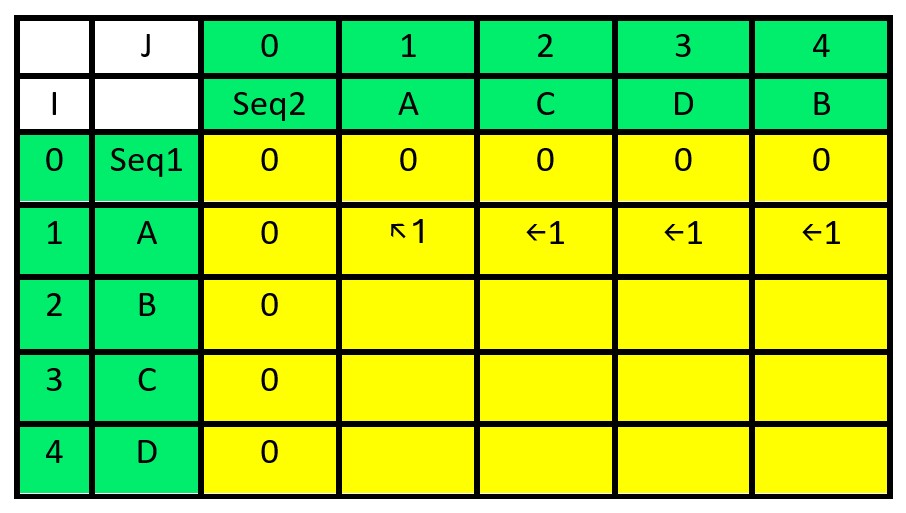
For i=1 (character A in seq1):
- For j=1 (character A in seq2): dp[1][1] = 1 and directions[1][1] = “↖” (characters match).
Whenever a character matches, the cell contains a North-West arrow (↖), and the value in that cell is the value from the North-West cell plus 1.
- For j=2 (character C in seq2): dp[1][2] = 1 and directions[1][2] = “←” (Take the maximum value from the cell directly above or the cell directly to the left.).
- For j=3 (character D in seq2): dp[1][3] = 1 and directions[1][3] = “←” (Take the maximum value from the cell directly above or the cell directly to the left.).
- For j=4 (character B in seq2): dp[1][4] = 1 and directions[1][4] = “←” (Take the maximum value from the cell directly above or the cell directly to the left.).
.
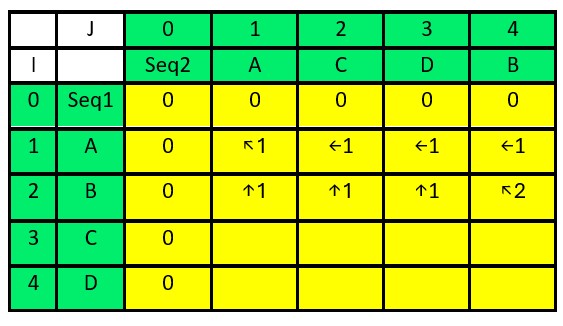
For i=2 (character B in seq1):
- For j=1 (character A in seq2, unmatched): dp[2][1] = dp[1][1] = 1, directions[2][1] = “↑”
- For j=2 (character C in seq2, unmatched): dp[2][2] = dp[2][1] = 1, directions[2][2] = “↑”
- For j=3 (character D in seq2, unmatched): dp[2][3] = dp[2][2] = 1, directions[2][3] = “↑”
- For j=4 (character B in seq2, matched): dp[2][4] = dp[1][3] + 1 = 2, directions[2][4] = “↖”
.
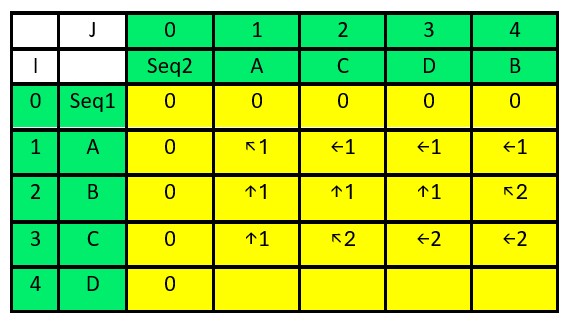
For i=3 (character C in seq1):
- For j=1 (character A in seq2): dp[3][1] = dp[2][1] = 1, directions[3][1] = “↑”
- For j=2 (character C in seq2): dp[3][2] = dp[2][1] + 1 = 2, directions[3][2] = “↖”
- For j=3 (character D in seq2): dp[3][3] = dp[3][2] = 2, directions[3][3] = “←”
- For j=4 (character B in seq2): dp[3][4] = dp[3][3] = 2, directions[3][4] = “←”
.
For i=4 (character D in seq1):
- For j=1 (character A in seq2): dp[4][1] = dp[3][1] = 1, directions[4][1] = “↑”
- For j=2 (character C in seq2): dp[4][2] = dp[3][2] = 2, directions[4][2] = “↑”
- For j=3 (character D in seq2): dp[4][3] = dp[3][2] + 1 = 3, directions[4][3] = “↖”
- For j=4 (character B in seq2): dp[4][4] = dp[4][3] = 3, directions[4][4] = “←”
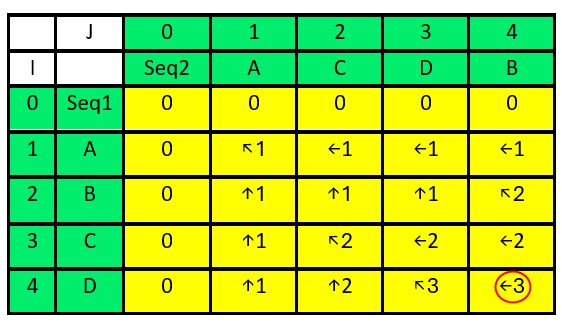
The final answer is located in the last cell of the dynamic programming table, which is highlighted in red. The length of the Longest Common Subsequence (LCS) for Sequence 1 and Sequence 2 is 3.
Also, the lcs is ACD because –
- Start from the last cell and follow the directions of arrow.
- If the direction is “↖” (North-West), it means a character match. Add this character to the LCS.
- If the direction is “↑” (Up), move up.
- If the direction is “←” (Left), move left.
- The collected characters are D, C, and A. Reverse this sequence to get the LCS – ACD.
.
Source Code of Longest Common Sub-sequence
BOOKS



