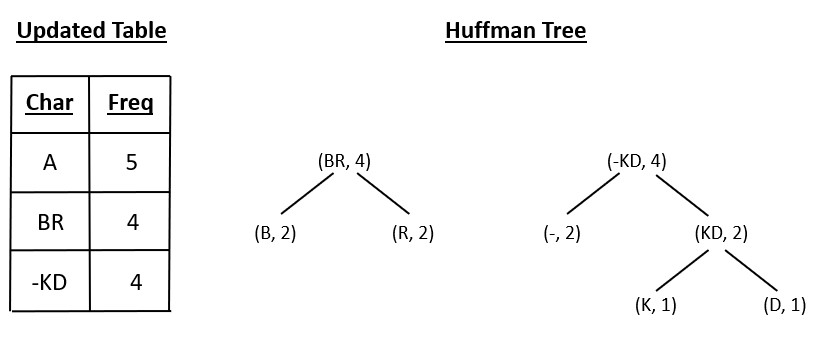
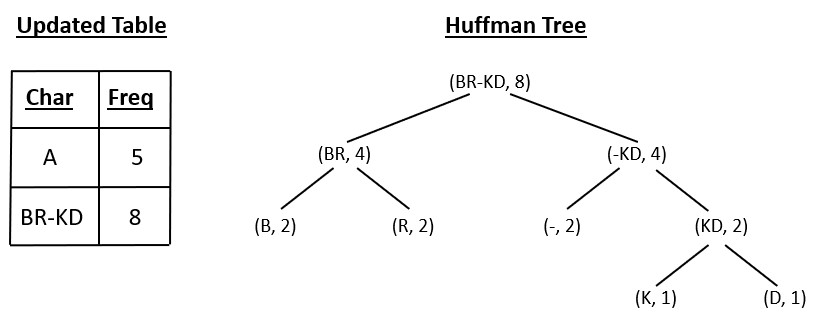
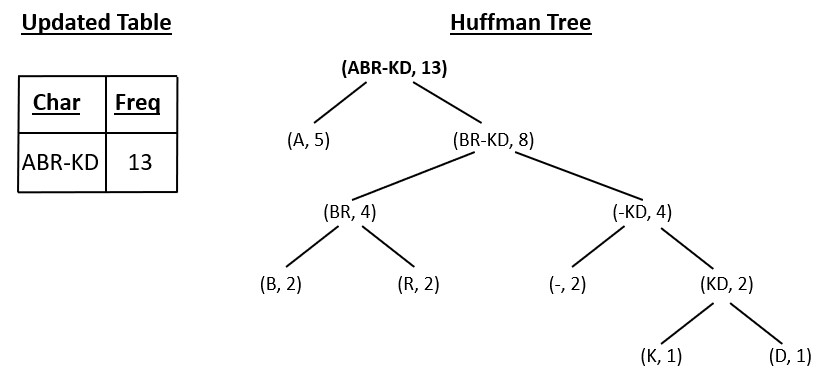
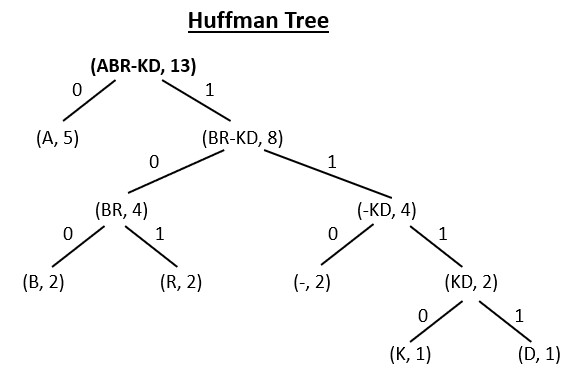
C
// COMPUTER GEEK – compgeek.co.in
// Write a program for Huffman Tree
#include <stdio.h>
#include <stdlib.h>
// Define the node structure for Huffman tree
typedef struct Node
{
char data; // Character
int freq; // Frequency
struct Node *left; // Left child
struct Node *right; // Right child
} Node;
// Function to create a new node
Node* createNode(char data, int freq)
{
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->freq = freq;
newNode->left = NULL;
newNode->right = NULL;
return newNode;
}
int main()
{
int numChars;
// User will enter the number of characters
printf(“Enter the number of characters: “);
scanf(“%d”, &numChars);
// Create an array of nodes to store character frequencies
Node* nodes[numChars];
// User will enter character frequencies
for (int i = 0; i < numChars; i++)
{
char character;
int frequency;
printf(“Enter character %d: “, i + 1);
scanf(” %c”, &character); // Space before %c to consume newline
printf(“Enter frequency for character %c: “, character);
scanf(“%d”, &frequency);
// Create a new node for the character and frequency
nodes[i] = createNode(character, frequency);
}
// Construct the Huffman tree
while (numChars > 1)
{
// Find the two nodes with the lowest frequencies
int min1 = 0, min2 = 1;
if (nodes[min1]->freq > nodes[min2]->freq) {
int temp = min1;
min1 = min2;
min2 = temp;
}
for (int i = 2; i < numChars; i++)
{
if (nodes[i]->freq < nodes[min1]->freq)
{
min2 = min1;
min1 = i;
}
else if (nodes[i]->freq < nodes[min2]->freq)
{
min2 = i;
}
}
// Create a new internal node and update the array
Node* internalNode = createNode(‘$’, nodes[min1]->freq + nodes[min2]->freq);
internalNode->left = nodes[min1];
internalNode->right = nodes[min2];
// Remove the used nodes and add the new internal node
nodes[min1] = internalNode;
nodes[min2] = nodes[numChars – 1];
numChars–;
}
// Print the Huffman codes
printf(“Huffman Codes:\n”);
// A function to traverse the Huffman tree and print codes
void printCodes(Node* root, int code[], int top)
{
if (root->left)
{
code[top] = 0;
printCodes(root->left, code, top + 1);
}
if (root->right)
{
code[top] = 1;
printCodes(root->right, code, top + 1);
}
if (!root->left && !root->right)
{
printf(“%c: “, root->data);
for (int i = 0; i < top; i++)
{
printf(“%d”, code[i]);
}
printf(“\n”);
}
}
int code[numChars], top = 0;
printCodes(nodes[0], code, top);
return 0;
}
C++
// COMPUTER GEEK – compgeek.co.in
// Write a program for Huffman Tree
#include <iostream>
#include <map>
#include <queue>
// Define the node structure for Huffman tree
struct Node
{
char data; // Character
int freq; // Frequency
Node* left; // Left child
Node* right; // Right child
Node(char data, int freq) : data(data), freq(freq), left(nullptr), right(nullptr) {}
};
// Comparison function for the priority queue
struct CompareNode
{
bool operator()(Node* const& a, Node* const& b)
{
return a->freq > b->freq;
}
};
// Function to construct the Huffman tree
Node* buildHuffmanTree(std::map<char, int>& frequencies)
{
std::priority_queue<Node*, std::vector<Node*>, CompareNode> pq;
for (auto const& pair : frequencies)
{
pq.push(new Node(pair.first, pair.second));
}
while (pq.size() > 1)
{
Node* left = pq.top();
pq.pop();
Node* right = pq.top();
pq.pop();
Node* internalNode = new Node(‘$’, left->freq + right->freq);
internalNode->left = left;
internalNode->right = right;
pq.push(internalNode);
}
return pq.top();
}
// Function to print Huffman codes
void printHuffmanCodes(Node* root, std::string code)
{
if (!root)
{
return;
}
if (root->data != ‘$’)
{
std::cout << root->data << “: ” << code << std::endl;
}
printHuffmanCodes(root->left, code + “0”);
printHuffmanCodes(root->right, code + “1”);
}
int main()
{
int numChars;
// User will enter the number of characters
std::cout << “Enter the number of characters: “;
std::cin >> numChars;
std::map<char, int> frequencies;
// User will enter character frequencies
for (int i = 0; i < numChars; i++)
{
char character;
int frequency;
std::cout << “Enter character ” << i + 1 << “: “;
std::cin >> character;
std::cout << “Enter frequency for character ” << character << “: “;
std::cin >> frequency;
frequencies[character] = frequency;
}
// Build the Huffman tree
Node* root = buildHuffmanTree(frequencies);
// Print the Huffman codes
std::cout << “Huffman Codes:” << std::endl;
printHuffmanCodes(root, “”);
return 0;
}
Java
// COMPUTER GEEK – compgeek.co.in
// Write a program for Huffman Tree
import java.util.PriorityQueue;
import java.util.Scanner;
class Node
{
char data;
int freq;
Node left;
Node right;
public Node(char data, int freq)
{
this.data = data;
this.freq = freq;
left = null;
right = null;
}
}
class Huffman
{
public static Node createNode(char data, int freq) {
return new Node(data, freq);
}
public static void printHuffmanCodes(Node root)
{
int[] code = new int[256];
int top = 0;
printCodes(root, code, top);
}
private static void printCodes(Node node, int[] code, int top)
{
if (node.left != null) {
code[top] = 0;
printCodes(node.left, code, top + 1);
}
if (node.right != null)
{
code[top] = 1;
printCodes(node.right, code, top + 1);
}
if (node.left == null && node.right == null)
{
System.out.print(node.data + “: “);
for (int i = 0; i < top; i++)
{
System.out.print(code[i]);
}
System.out.println();
}
}
public static void main(String[] args)
{
Scanner scanner = new Scanner(System.in);
int numChars;
System.out.print(“Enter the number of characters: “);
numChars = scanner.nextInt();
Node[] nodes = new Node[numChars];
for (int i = 0; i < numChars; i++)
{
char character;
int frequency;
System.out.print(“Enter character ” + (i + 1) + “: “);
character = scanner.next().charAt(0);
System.out.print(“Enter frequency for character ” + character + “: “);
frequency = scanner.nextInt();
nodes[i] = createNode(character, frequency);
}
while (numChars > 1)
{
int min1 = 0, min2 = 1;
if (nodes[min1].freq > nodes[min2].freq)
{
int temp = min1;
min1 = min2;
min2 = temp;
}
for (int i = 2; i < numChars; i++)
{
if (nodes[i].freq < nodes[min1].freq)
{
min2 = min1;
min1 = i;
}
else if (nodes[i].freq < nodes[min2].freq)
{
min2 = i;
}
}
Node internalNode = createNode(‘$’, nodes[min1].freq + nodes[min2].freq);
internalNode.left = nodes[min1];
internalNode.right = nodes[min2];
nodes[min1] = internalNode;
nodes[min2] = nodes[numChars – 1];
numChars–;
}
printHuffmanCodes(nodes[0]);
}
}
Python
# COMPUTER GEEK – compgeek.co.in
# Write a program for Huffman Tree
class Node:
def __init__(self, data, freq):
self.data = data
self.freq = freq
self.left = None
self.right = None
def create_node(data, freq):
new_node = Node(data, freq)
return new_node
def huffman_codes(root):
code = [0] * 256
top = 0
def print_codes(node, code, top):
if node.left:
code[top] = 0
print_codes(node.left, code, top + 1)
if node.right:
code[top] = 1
print_codes(node.right, code, top + 1)
if not node.left and not node.right:
print(f”{node.data}: {”.join(map(str, code[:top]))}”)
print(“Huffman Codes:”)
print_codes(root, code, top)
def main():
num_chars = int(input(“Enter the number of characters: “))
nodes = []
for i in range(num_chars):
character = input(f”Enter character {i + 1}: “)
frequency = int(input(f”Enter frequency for character {character}: “))
nodes.append(create_node(character, frequency))
while num_chars > 1:
min1, min2 = 0, 1
if nodes[min1].freq > nodes[min2].freq:
min1, min2 = min2, min1
for i in range(2, num_chars):
if nodes[i].freq < nodes[min1].freq:
min2 = min1
min1 = i
elif nodes[i].freq < nodes[min2].freq:
min2 = i
internal_node = create_node(‘$’, nodes[min1].freq + nodes[min2].freq)
internal_node.left = nodes[min1]
internal_node.right = nodes[min2]
nodes[min1] = internal_node
nodes[min2] = nodes[num_chars – 1]
num_chars -= 1
huffman_codes(nodes[0])
if __name__ == “__main__”:
main()