


SYLLABUS
System calls, processes, threads, inter‐process communication, concurrency and synchronization. Deadlock. CPU and I/O scheduling. Memory management and virtual memory. File systems.
Q1 – Which of the following statements about threads is/are TRUE?
(A) Threads can only be implemented in kernel space
(B) Each thread has its own file descriptor table for open files
(C) All the threads belonging to a process share a common stack
(D) Threads belonging to a process are by default not protected from each other
Ans – (D)
Explanation –
The statement presented as (A) is incorrect. Threads may be implemented in user space and kernel space, depending on the operating system and thread library. It is, therefore, incorrect to say threads can only be implemented in kernel space.
Statement (B) is incorrect. Threads in the same process share the same file descriptor table. Thus, all threads of a process can access the same set of open files.
The statement represented as (C) is also incorrect. Threads do not share the same stack. Each thread has its own stack, this stack is used to store function calls, and local variables. However, they share the same address space, heap, and global variables.
The statement represented as (D) is true. Threads in the same process are not protected from each other by default. Because they share the same memory space, one thread can overwrite data used by another thread; this will lead to bugs if not handled properly. Therefore, the correct answer is (D).
Q2 – Which of the following process state transitions is/are NOT possible?
(A) Running to Ready
(B) Waiting to Running
(C) Ready to Waiting
(D) Running to Terminated
Ans – (B, C)
Explanation –
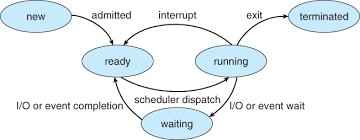
Option (B) Waiting to Running – It is NOT possible to transition directly between these two states. In order for a process that is in the Waiting (or blocked) state to transition to the Running state, it first has to transition to the Ready state after the event which was causing it to wait is completed, and then the scheduler has to select that process to transition to Running.
Option (C) Ready to Waiting – It is also NOT possible to transition directly between these two states. A process can only transition between Ready and Running in the Ready state, and if it needs to wait (for I/O for example) it has to transition between Running and Waiting. Therefore, a direct transition from Ready to Waiting is invalid.
Q3 – Consider the following two threads T1 and T2 that update two shared variables a and b. Assume that initially a = b = 1.
Though context switching between threads can happen at any time, each statement of T1 or T2 is executed atomically without interruption.
T1
a = a + 1;
b = b + 1;
T2
b = 2 * b;
a = 2 * a;
Which one of the following options lists all the possible combinations of values of a and b after both T1 and T2 finish execution?
(A) (a = 4, b = 4); (a = 3, b = 3); (a = 4, b = 3)
(B) (a = 3, b = 4); (a = 4, b = 3); (a = 3, b = 3)
(C) (a = 4, b = 4); (a = 4, b = 3); (a = 3, b = 4)
(D) (a = 2, b = 2); (a = 2, b = 3); (a = 3, b = 4)
Ans – (A)
Explanation –
There are 6 orders in which T1 and T2 finishes execution.
Initially a = 1, b = 1
1. T1 full finish, T2 full finish
a = a + 1 (a = 2)
b = b + 1 (b = 2)
b = 2 * b (b = 4)
a = 2 * a (a = 4)
(a = 4, b = 4)
.
2. T2 full finish, T1 full finish
b = 2 * b (b = 2)
a = 2 * a (a = 2)
a = a + 1 (a = 3)
b = b + 1 (b = 3)
(a = 3, b = 3)
.
3. T1 1st instr, T2 1st instr, T1 2nd instr, T2 2nd instr
a = a + 1 (a = 2)
b = 2 * b (b = 2)
b = b + 1 (b = 3)
a = 2 * a (a = 4)
(a = 4, b = 3)
.
4. T2 1st instr, T1 1st instr, T2 2nd instr, T1 2nd instr
b = 2 * b (b = 2)
a = a + 1 (a = 2)
a = 2 * a (a = 4)
b = b + 1 (b = 3)
(a = 4, b = 3)
.
5. T1 1st instr, T2 full finish, T1 2nd instr
a = a + 1 (a = 2)
b = 2 * b (b = 2)
a = 2 * a (a = 4)
b = b + 1 (b = 3)
(a = 4, b = 3)
.
6. T2 1st instr, T1 full finish, T2 2nd instr
b = 2 * b (b = 2)
a = a + 1 (a = 2)
b = b + 1 (b = 3)
a = 2 * a (a = 3)
(a = 3, b = 3)
Option (A) is the answer.
Q4 – Consider the following read-write schedule 𝑆 over three transactions 𝑇1, 𝑇2, and 𝑇3, where the subscripts in the schedule indicate transaction IDs:
𝑆: 𝑟1(𝑧); 𝑤1(𝑧); 𝑟2(𝑥); 𝑟3(𝑦); 𝑤3(𝑦); 𝑟2(𝑦); 𝑤2(𝑥); 𝑤2(𝑦);
Which of the following transaction schedules is/are conflict equivalent to 𝑆 ?
(A) 𝑇1 𝑇2 𝑇3
(B) 𝑇1 𝑇3 𝑇2
(C) 𝑇3 𝑇2 𝑇1
(D) 𝑇3 𝑇1 𝑇2
Ans – (B, C, D)
Explanation – To find out which transaction schedules are conflict equivalent to schedule 𝑆, which maintains the ordering of the conflicting operations between transactions.
The schedule 𝑆 is: r₁(z); w₁(z); r₂(x); r₃(y); w₃(y); r₂(y); w₂(x); w₂(y).
In schedule 𝑆, when two operations from different transactions access a data item and at least one of them is a write, the two operations are in conflict.
The key conflicts are w₃(y) from transaction T3 precedes r₂(y) and w₂(y) from transaction T2, meaning that T3 must precede T2 in any conflict equivalent schedule. T1 accesses only z, meaning it does not conflict with T2 or T3. Therefore, it can appear anywhere.
Option (A), T1 T2 T3 is not conflict equivalent because T3 is after T2, and the ordering for the conflicts is not present.
Option (B), T1 T3 T2 does keep all of the ordering of the conflicts.
Option (C), T3 T2 T1 supports the conflict between T3 and T2 in addition to T3. Where T1 can appear anywhere. Finally,
Option (D), T3 T1 T2, also keeps T3 preceding T2, and T1 can also appear anywhere.
Q5 – Consider two set-associative cache memory architectures: WBC, which uses the write back policy, and WTC, which uses the write through policy. Both of them use the LRU (Least Recently Used) block replacement policy. The cache memory is connected to the main memory.
Which of the following statements is/are TRUE?
(A) A read miss in WBC never evicts a dirty block
(B) A read miss in WTC never triggers a write back operation of a cache block to main memory
(C) A write hit in WBC can modify the value of the dirty bit of a cache block
(D) A write miss in WTC always writes the victim cache block to main memory before loading the missed block to the cache
Ans – (B, C)
Explanation – In this scenario, there are two cache architectures: WBC (Write-Back Cache) and WTC (Write-Through Cache), both using the LRU replacement policy.
In a Write-Back Cache, due to the LRU replacement policy, if there is an eviction of a dirty block, it will happen when there is a read miss. Therefore option (A) is not true.
In a write-through cache, all writes go to the main memory, which means that we do not ever mark cache blocks as dirty in a write-through cache. As such, during a read miss, we do not write back any block to main memory because there is nothing dirty. Therefore option (B) is true.
In a write-back cache, when we hit on a write, we update the cache block with the new data. We may also set the dirty bit. Thus, option (C) is true.
Option (D) is not true. A Write-Through Cache does not have dirty blocks, therefore, a write miss does not mean that the victim block must be written to memory.
Q6 – Consider a 512 GB hard disk with 32 storage surfaces. There are 4096 sectors per track and each sector holds 1024 bytes of data. The number of cylinders in the hard disk is _________.
Ans – (4096)
Explanation – Number of cylinders = Total disk size / data per cylinder
Number of cylinders = (512 * 10243)/(32 * 4096 * 1024)
There are 4096 cylinders
Q7 – The baseline execution time of a program on a 2 GHz single core machine is 100 nanoseconds (ns). The code corresponding to 90% of the execution time can be fully parallelized. The overhead for using an additional core is 10 ns when running on a multicore system.
Assume that all cores in the multicore system run their share of the parallelized code for an equal amount of time.
The number of cores that minimize the execution time of the program is ________.
Ans – (3)
Explanation – You have a program that takes 100 nanoseconds to run on a single-core computer.
Out of the total 100 ns, 90 ns of code can be accelerated through multi-core (parallel code) and 10 ns of the code always runs on a single core (serial code).
Also when you add one more core, it takes 10 ns of overhead (extra time to manage cores).
Now let’s say you use n cores.
Then the total time is – 10 ns for the serial part (cannot improve), 90/n ns for the parallel part (because you are distributing the work among cores),10 × (n – 1) ns extra overhead time because you are using more cores. So total time = 10 + 90/n + 10(n−1).
If n=1 → Time = 100 ns
If n=2 → Time= 10 + 45 + 10 = 65 ns
If n=3 → Time= 10 + 30 + 20 = 60 ns (minimum)
If n=4 → Time= 10 + 22.5 + 30 = 62.5 ns.
If n=5 → Time= 10 + 18 + 40 = 68 ns.
So, the optimal number of cores is 3 because it takes the least time.
Q8 – A given program has 25% load/store instructions. Suppose the ideal CPI (cycles per instruction) without any memory stalls is 2. The program exhibits 2% miss rate on instruction cache and 8% miss rate on data cache. The miss penalty is 100 cycles. The speedup (rounded off to two decimal places) achieved with a perfect cache (i.e., with NO data or instruction cache misses) is _________.
Ans – (3.00)
Explanation – Since all instructions go through the instruction cache, the instruction cache miss penalty per instruction is 0.02 x 100 = 2 cycles.
Only 25% of the instructions are load/store, so the data cache miss penalty per instruction is 0.25 x 0.08 x 100 = 2 cycles.
So, the actual CPI, or cycles per instruction (including memory stalls) is 2 (the ideal CPI) + 2 (the instruction stall penalty) + 2 (the data stall penalty) = 6.
The speedup = actual CPI / ideal CPI. Therefore, speedup = 6/2 = 3.00 (rounded off to two decimal places).
Q9 – Consider the following code snippet using the fork() and wait() system calls. Assume that the code compiles and runs correctly, and that the system calls run successfully without any errors.
int x = 3;
while(x > 0) {
fork();
printf(“hello”);
wait(NULL);
x–;
}
The total number of times the printf statement is executed is ___________.
Ans – (14)
Explanation –
Iteration 1 – When x = 3, fork happens.
So, parent and child, 2 processes are there and two printf command execute. Parent waits child to finish.
Iteration 2 –
When x = 2, fork happens again in parent and child.
So, 4 processes are there and four printf command execute. Parent waits child to finish.
Iteration 3 –
When x = 3, fork happens again in 4 processes.
So, 8 processes are there and eight printf command execute. Parent waits child to finish.
So, total 14 printf commands execute.
Q10 – Consider a memory management system that uses a page size of 2 KB. Assume that both the physical and virtual addresses start from 0. Assume that the pages 0, 1, 2, and 3 are stored in the page frames 1, 3, 2, and 0, respectively. The physical address (in decimal format) corresponding to the virtual address 2500 (in decimal format) is _________.
Ans – (6596)
Explanation –
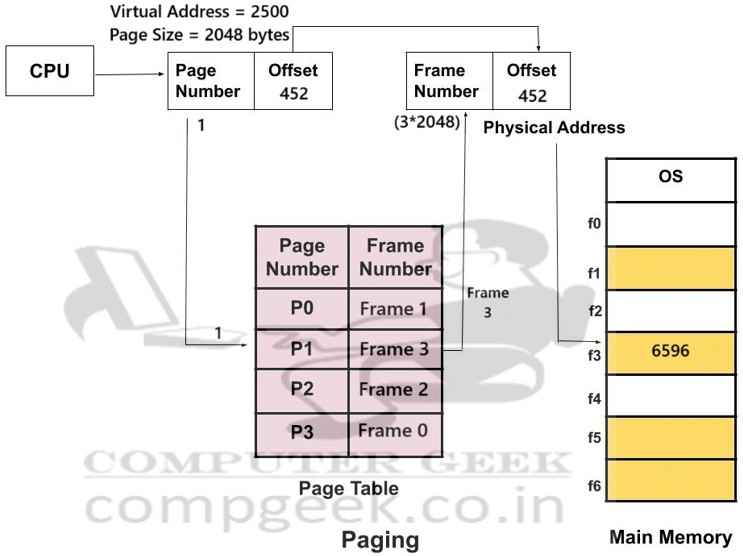
The CPU produces a logical address (also called a virtual address).
Logical (virtual) address is split into two parts
- Page Number
- Offset within that page
Virtual address = 2500 (in decimal)
Page size = 2 KB = 2048 bytes
Page number = 2500 ÷ 2048 = 1 (quotient)
Offset = 2500 % 2048 = 452
So, virtual address 2500 belongs to virtual page 1, with offset = 452.
Page to frame mapping:
Page 0 → Frame 1
Page 1 → Frame 3
Page 2 → Frame 2
Page 3 → Frame 0
Physical address = (frame number x page size) + offset
= (3 x 2048) + 452
= 6144 + 452
= 6596