


Collision Handling Techniques
Hashing looks magical at first. You give a key, and data appears in constant time. Feels like teleportation for information. But then comes the twist in the story.
“Two different keys land in the same index. This is called collision in hashing.”
.
Collision happens when two different keys produce the same hash index.
For example – If we use a hash function h(k) = k mod 7
like,
First number, 14 mod 7 = 0th index
Second number, 35 mod 10 = 0th index
Then, both keys want to go to index 0. But the array has only one slot at index 0. So what now? That situation is called a collision.
Collision is not a bug. It is natural. And it must happen in real systems.
.
Why Collision Happens
Collisions happen because –
- The hash table size is limited.
- The number of possible keys is very large.
- A hash function compresses a large key space into a small index space.
Even if your hash function is excellent, collisions are unavoidable. And this brings us to a beautiful mathematical idea.
.
Pigeonhole Principle – The Core Idea
The Pigeonhole Principle is a simple but powerful concept in mathematics.
It says –
“If you have more pigeons than pigeonholes, at least one pigeonhole must contain more than one pigeon.”
That is, if you insert 11 keys into a hash table of size 10, at least one index must store more than one key. This is not bad luck. It is mathematics. Collision handling techniques are simply smart ways to manage this reality.
.
Collision Handling Techniques
Can be classified as –
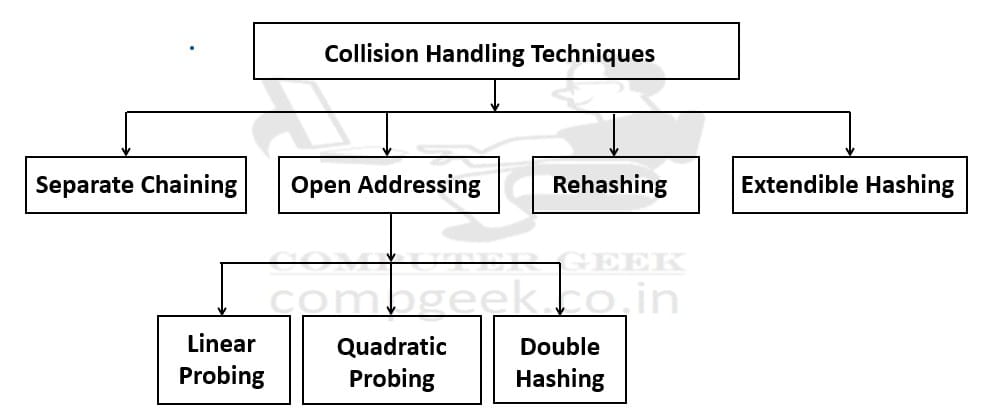
In this post, we focus deeply on Separate Chaining, also called Closed Addressing.
.
Separate Chaining – Closed Addressing
“Separate Chaining is a collision handling technique where each index of the hash table stores a linked list. If multiple keys map to the same index, we store them in that linked list. Instead of fighting over one seat, they sit in a small queue.”
.
Input is = {10, 15, 3, 12, 14, 24, 7, 37}
Suppose that hash function is h(k) = k mod 7
Also, we have a linked list method in each of the index of the hash table. Linked list is called a bucket and the bucket of index 0 is a separate chain to the index 1.
Linked List Method
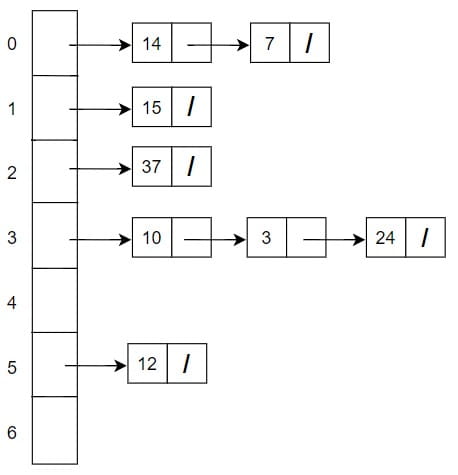
Each array index is called a bucket and each bucket contains a linked list. If keys 14 and 7 both map to index 7, then
Index 0 → 14 → 7
Both values are stored safely. No overwriting. No panic.
But the insertion, searching and deletion has a big impact, their worst-case time complexity is O(n).
.
1. Insertion in Separate Chaining
Steps –
- Compute hash index.
- Go to that index.
- Insert the key into the linked list at that bucket.
Insertion is usually done at the beginning of the linked list because it is faster.
Time complexity for insertion –
- Best case – O(1)
- Average case – O(1)
- Worst case – O(n) if all keys go to same bucket
But with a good hash function and proper table size, average case remains constant.
.
2. Searching in Separate Chaining
Steps –
- Compute hash index.
- Go to that bucket.
- Traverse the linked list.
- Compare keys one by one.
Time complexity –
- Best case – O(1)
- Average case – O(1 + α)
- Worst case – O(n)
Here α (alpha) is called load factor.
Load Factor = Number of elements / Table size. If load factor is small, searching is very fast.
.
3. Deletion in Separate Chaining
Steps –
- Find the bucket using hash function.
- Traverse the linked list.
- Remove the node.
Deletion time complexity –
- Best case – O(1)
- Average case – O(1)
- Worst case – O(n)
Linked list makes deletion flexible and easy.
.
Advantages of Separate Chaining
- Easy to implement.
- Simple deletion.
- Table never becomes completely full.
- Less clustering problem compared to open addressing.
- Works well even if load factor is greater than 1.
- Many standard library implementations of hash maps use chaining internally.
Disadvantages of Separate Chaining
- Extra memory needed for linked list pointers.
- Cache performance is not as good as open addressing.
- If load factor becomes very high, performance decreases.
So it is not perfect, but it is stable and reliable.
BOOKS



