


SYLLABUS
Machine instructions and addressing modes. ALU, data‐path and control unit. Instruction pipelining, pipeline hazards. Memory hierarchy: cache, main memory and secondary storage; I/O interface (interrupt and DMA mode)
Q1 – Which one of the following statements is FALSE?
(A) In the cycle stealing mode of DMA, one word of data is transferred between an I/O device and main memory in a stolen cycle
(B) For bulk data transfer, the burst mode of DMA has a higher throughput than the cycle stealing mode
(C) Programmed I/O mechanism has a better CPU utilization than the interrupt driven I/O mechanism
(D) The CPU can start executing an interrupt service routine faster with vectored interrupts than with non-vectored interrupts.
(GATE 2024 CS1)
Ans – (C)
Explanation – Option A – In cycle stealing mode of Direct Memory Access (DMA), the DMA controller momentarily gains control over the system bus to transfer a word of data, one word at a time, between an I/O device and main memory. Since it is performing the transfer of one word at a time, we say that this statement is true.
Option B – Burst Mode DMA allows the continuous transfer of data without CPU intervention, resulting in improved throughput. Cycle Stealing DMA, on the other hand, transfers one word at a time, which is slower than burst mode. Since the throughput in burst streaming is improved compared to cycle stealing, we can say that the statement is true.
Option C – Programmed I/O requires the CPU to actively wait (polling) for the I/O operation to finish. Interrupt-driven I/O does not require the CPU to wait inactively, allowing it to continue executing instructions until the device interrupts the CPU when it is ready. Since interrupt-driven I/O leads to better CPU utilization than programmed I/O, we can conclude the statement is false.
Option D – Vectored Interrupts provide the address for Interrupt Service Routines (ISRs) directly, allowing the CPU to minimize delay caused to begin execution of the interrupt. Non-vectored Interrupts may require the CPU to poll or read the ISR address before it starts its execution, adding additional delay to the handling of the interrupt. Since vectored interrupts allow faster ISR execution, this statement is true.
Q2 – Consider a 5-stage pipelined processor with Instruction Fetch (IF), Instruction Decode (ID), Execute (EX), Memory Access (MEM), and Register Writeback (WB) stages.
Which of the following statements about forwarding is/are CORRECT?
(A) In a pipelined execution, forwarding means the result from a source stage of an earlier instruction is passed on to the destination stage of a later instruction
(B) In forwarding, data from the output of the MEM stage can be passed on to the input of the EX stage of the next instruction
(C) Forwarding cannot prevent all pipeline stalls
(D) Forwarding does not require any extra hardware to retrieve the data from the pipeline stages
(GATE 2024 CS1)
Ans – (A, B, C)
Explanation – In a 5-stage pipelined CPU consisting of front-end stages (IF & ID) and back-end stages (EX, MEM, WB), forwarding can mitigate pipeline stalls by allowing the processor to route data directly from one pipeline stage to another without going through every pipeline stage. Hence, option (A) is true.
Option (B) is also true, as a common scenario for forwarding is forwarding the output of the MEM stage of one instruction to the EX-stage of another instruction if the data is required. Option (C) is true in acknowledging that forwarding does help reduce data hazards to avoid stalls in many circumstances, however, forwarding is unable to resolve every situation, particularly with load-use hazards in the situation where the data is still being generated in the previous load instruction, and have not yet been fetched into the register.
Option (D) is false. Forwarding that helps to minimize stalls does come at the cost of extra hardware for multiplexers and forwarding logic and does add some extra functionality to detect the hazards a route data from pipeline stage to pipeline stage. The correct answer is, therefore, A, B, and C.
Q3 – Consider the following pseudo-code.
𝐿1: 𝑡1= −1
𝐿2: 𝑡2 = 0
𝐿3: 𝑡3 = 0
𝐿4: 𝑡4 = 4∗𝑡3
𝐿5: 𝑡5 = 4∗𝑡2
𝐿6: 𝑡6 = 𝑡5∗𝑀
𝐿7: 𝑡7 = 𝑡4+𝑡6
𝐿8: 𝑡8 = 𝑎[𝑡7]
𝐿9: if 𝑡8 <= 𝑚𝑎𝑥 goto 𝐿11
𝐿10: 𝑡1 = 𝑡8
𝐿11: 𝑡3 = 𝑡3+1
𝐿12: if 𝑡3 < 𝑀 goto 𝐿4
𝐿13: 𝑡2 = 𝑡2+1
𝐿14: if 𝑡2 < 𝑁 goto 𝐿3
𝐿15: 𝑚𝑎𝑥 = 𝑡1
Which one of the following options CORRECTLY specifies the number of basic blocks and the number of instructions in the largest basic block, respectively ?
(A) 6 and 6
(B) 6 and 7
(C) 7 and 7
(D) 7 and 6
(GATE 2024 CS1)
Ans – (D)
Explanation –
A basic block is defined as a series of instructions that
- Execute sequentially with no jumps or branches in between.
- It must start execution only when control comes from outside the block (one instruction is executed after another).
- Execution of a basic block ends when either:
A jump, goto, or if statement occurs,
Or the next instruction is branch target.
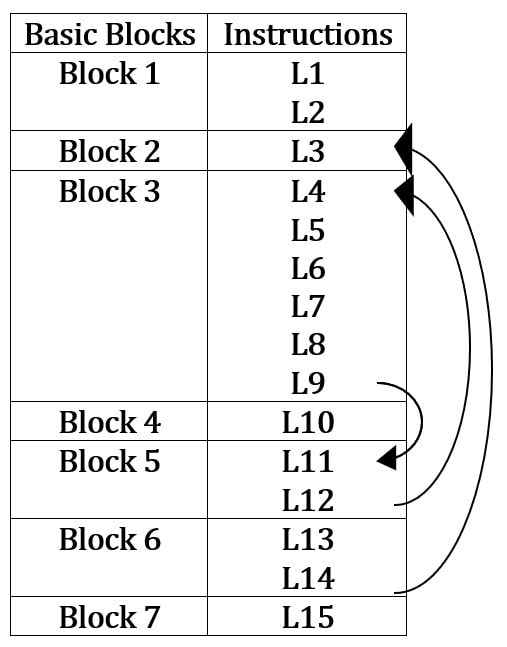
There are 7 blocks and the largest block 3 has 6 instructions.
Q4 – Consider the operators ◊ and □ defined by
𝑎◊𝑏 = 𝑎+2𝑏, 𝑎□𝑏 = 𝑎𝑏, for positive integers.
Which of the following statements is/are TRUE?
(A) Operator ◊ obeys the associative law
(B) Operator □ obeys the associative law
(C) Operator ◊ over the operator □ obeys the distributive law
(D) Operator □ over the operator ◊ obeys the distributive law
(GATE 2024 CS1)
Ans – (B, D)
Explanation – There are two operators we have: a⋄b=a + 2b and a□b=ab. The operator ⋄ is not associative.
(a⋄b)⋄c = a + 2b + 2c
a⋄(b⋄c) = a + 2b + 4c
so, option (A) is false.
The operator □ is multiplication and will be associative (a□b)□c=a□(b□c), so option (B) is true.
Next, we will see about the distributive laws. For ⋄ over □ we see that a⋄(b□c) is not equal to a⋄b□a⋄c.
a⋄(b□c) = a + 2bc
a⋄b□a⋄c = (a + 2b)(a + 2c) = a2 + 2(ac + ba) + 4bc.
so option (C) is false.
However, we can see that □ does satisfy the distributive law over ⋄. that is, a□(b⋄c)=(a□b)⋄(a□c) (D) is true.
a□(b⋄c) = ab + 2ac.
(a□b)⋄(a□c) = ab ⋄ ac = ab + 2ac.
Therefore, the true answers are (B) and (D).