


Q1 – What is the probability that a positive integer selected at random from the set of positive integer not exceeding 100 is divisible by either 2 or 5?
10/5
3/5
2/5
1/5
Ans – (2)
Explanation – We count numbers divisible by 2, 5, and both 2 and 5.
Numbers divisible by 2 is, 100/2 = 50
Numbers divisible by 5 is, 100/5 = 20
Numbers divisible by 2 and 5 means 10 is, 100/10 = 10
Apply the inclusion – exclusion formula, we get
- N(2 V 5) = N(2) + N(5) – N(10)
- N(2 V 5) = 50 + 20 – 10
- N(2 V 5) = 60
- P(2 V 5) = 60/100 = 3/5.
Q2 – Which of the following is not a palindromic subsequence of the string “ababcdabba”?
abcba
abba
abbbba
adba
Ans – (3, 4)
Explanation –
String | a | b | a | b | c | d | a | b | b | a |
Index | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
Option 1 – abcba
String | a | b | c | b | a |
Index | 1 | 2 | 5 | 9 | 10 |
Option 2 – abba
String | a | b | b | a |
Index | 1 | 2 | 9 | 10 |
Option 3 – abbbba
String | a | b | b | b | b | a |
Index | 1 | 2 | 4 | 8 | 9 | 10 |
This is not correct.
Option 4 – adba
String | a | d | b | a |
Index | 1 | 6 | 9 | 10 |
This is not correct.
UGC NET corrects two options.
Q3 – Which of the following is TRUE?
The cost of searching an AVL tree is ϴ (log n) but that of binary search is 0(n)
The cost of searching an AVL tree in ϴ (log n) but that of complete binary tree is ϴ(n log n)
The cost of searching a binary tree is 0(log n) but that of AVL tree is ϴ (n)
The cost of searching an AVL tree is ϴ (n log n) but that of binary search tree is 0(n)
Ans – (1)
Explanation – Complexity of Search of AVL Trees is ϴ(log n)
An AVL tree is a self-balancing binary search tree (BST). The height of an AVL tree stays logarithmic (O(log n)) in the worst-case scenario. Naturally, searching in an AVL tree will have a time complexity of ϴ(log n).
Complexity of Searching in a Binary Search Tree in the worst case, the time becomes O(n).
A normal binary search tree (BST) may turn into an unbalanced one, and as such, if the tree is skewed, the time taken to search becomes O(n) in the worst case. This happens when all elements are inserted in sorted order, and it turns the tree into a linked list.
Q4 – What is the result of evaluating the postfix expression “43*25*+b-“ ?
8
14
10
5
Ans – (Can’t tell)
Explanation –
Expression | Stack (after operation) |
4 | 4 |
3 | 4, 3 |
* | 4*3 = 12 |
2 | 12, 2 |
5 | 12, 2, 5 |
* | 12, 2*5 = 10 |
+ | 12 + 10 = 22 |
b | 22, b |
– | 22 – b |
So, this postfix expression answer is 22 – b, which is not an option.
Q5 – Which of the following circuit is used to store one bit of data ?
Encoder
Decoder
Flip-Flop
Register
Ans – (3)
Explanation – A Flip-Flop is a sequential circuit that is used to store one bit of data. It has two stable states (0 or 1) and can be used as a basic memory unit in digital circuits. Flip-flops are widely used in registers, counters, and memory units.
Q6 – Identify the code sequence :
1010
1011
1001
1000
BCD
Excess-3
Gray
Excess-3 gray
Ans – (3)
Explanation – Gray code is a binary numeral system where two successive values differ in only one bit.
1010 -> 1011 last bit change (12 -> 13)
1011 -> 1001 Third bit change (13 -> 14)
1001 -> 1000 last bit change (14 -> 15)
Excess-3 Gray Code is a Gray code version of Excess-3, where each successive number differs by only one bit.
1010 -> 1011 last bit change (9 -> 10)
1011 -> 1001 Third bit change (10 -> 11)
1001 -> 1000 last bit change (11 -> 12)
But Excess-3 Gray code is not used in any manner in any operation. UGC just planted this, just to confuse you.
Other options –
BCD is a binary representation of decimal numbers where each digit is represented separately in 4 bits, and yes, the given code sequence has also 4 bits, but it is not in any type of sequence. 1010 is 10, 1011 is 11, 1001 is 9 and 1000 is 8.
Excess-3 is a modified BCD code where each BCD digit is incremented by 3.
Q7 – The microoperation which divides a signed binary number by 2 is:
Circular shift
Logical shift
Arithmetic shift right
Arithmetic shift left
Ans – (2)
Explanation – When it comes to signed binary division by 2, the thing to ensure is that the sign of the binary number (positive or negative) is preserved. This is done through an arithmetic right shift (ASR), in which all bits including the sign bit are shifted to the right.
Binary Representation – 1111 1100 (-4)
Arithmetic Shift Right (ASR) – 1111 1110 (Correct result is -2)
Q8 – A program that is used by other routines to accomplish a particular task, is called:
Micro program
Micro operation
Routine
Subroutine
Ans – (4)
Explanation – It is asking about some code which is to be invoked from other parts of a program to achieve a specific task.
In simple terms, a function or module is to be reused at different places in a program without rewriting a single piece of code.
A subroutine is a small piece of code designed to perform a certain task and is callable by other parts of a program. The same improves code reusability and modularity and eliminates code duplication in a program by calling the subroutine elsewhere at the point where we want to invoke that process.
Micro program – A low-level sequence of instructions used in the processor to execute machine instructions. This is not the answer.
Micro operation – A single, basic operation performed upon data in the CPU. So, this is also not the answer.
Routine – A general term for a sequence of instructions, though not necessarily designed to be used by other routines. That’s why not the answer.
Q9 – Consider a triangle PQR with coordinates as P(0, 0), Q(2, 2) and R(10, 4). If this triangle is to be magnified to four times its size while keeping R(10, 4) fixed, then the coordinates of the magnified triangle are
(-20, -12), Q(-20, -4) and R(10, 4)
(-30, -12), Q(-22, -4) and R(10, 4)
(-25, -10), Q(22, -4) and R(10, 4)
(30, -12), Q(-22, 4) and R(10, 4)
Ans – (2)
Explanation – In this question, we will use vectors to simplify the points.
Vector P = (0, 0)
Vector Q = (2, 2)
Vector R = (10, 4) and after magnification vector R is unchanged.
Vector R is fixed and vector P and Q are magnified by 4 times.
So, vector P – vector R = (0, 0) – (10, 4) = (-10, -4)
And, vector Q – vector R = (2, 2) – (10, 4) = (-8, -2)
By applying magnification of 4 times, we have got
Vector P – Vector R = 4*(-10, -4) = (-40, -16)
Vector P = (-40, -16) + Vector R
Vector P = (-40, -16) + (10, 4) = (-30, -12)
Also, Vector Q – Vector R = 4*(-8, -2) = (-32, -8)
Vector Q = (-32, -8) + Vector R
Vector Q = (-32, -8) + (10, 4) = (-22, -4)
Q10 – Which of the following statements is TRUE?
Virtual functions do not implement polymorphism
Virtual functions do not permit calling of derived class functions using a base class pointer
We can never build an object from a class containing a pure virtual function
Pure virtual functions can never have a body
Ans – (3)
Explanation – A virtual function is a type of function that is declared in the base class and is meant to be overridden in the derived class. The method is essential for runtime polymorphism to allow the correct function to be called for an object even if it is accessed through a pointer or reference to the base class.
In the first statement, actually the whole part of Calling functions that allow polymorphism depends on what we call virtual functions in C++. So, option 1 is false.
The second statement tells us that with virtual functions, we cannot call derived class functions using a base class pointer. This statement is also false since that was actually the very reason why virtual functions had been provided for us.
The fourth statement says that a pure virtual function can never have a body, which is false. Pure virtual function declaration uses = 0 syntax, while sometimes it may happen that a base class may give a pure virtual function an implementation.
The third statement, which says we can never build an object from a class containing a pure virtual function, is true. A class is considered an abstract class if it has at least one pure virtual function, and thus we can’t directly instantiate an abstract class. Rather, classes derived from it that provide implementations for all of its pure virtual functions can be instantiated.
Q11 – What is the output of the following program?
#include<stdio.h>
int main()
{ int i = 3;
while (i–)
{ int i = 10;
i–;
printf(“%d”, i);
}
printf(“%d”, i);
}
990
9990
999 – 1
99 – 1
Ans – (3)
Explanation – The outer loop, i = 3
1st iteration
The inner while loop has a condition (i–). So, original value of i is 3, so that condition becomes true and later on i is equal to 2.
Inside the while loop, there is a new variable i which is declared to 10, and decremented (i–) to 9 and in the inner loop 9 is printed.
2nd iteration
The outer loop, i is now 2.
The inner while loop has a condition (i–). So, original value of i is 2, so that condition becomes true and later on i is equal to 1.
Inside the while loop, there is a new variable i which is declared to 10, and decremented (i–) to 9 and in the inner loop 9 is printed.
3rd iteration
The outer loop, i is now 1.
The inner while loop has a condition (i–). So, original value of i is 1, so that condition becomes true and later on i is equal to 0.
Inside the while loop, there is a new variable i which is declared to 10, and decremented (i–) to 9 and in the inner loop 9 is printed.
4th iteration
The outer loop, i is now 0.
The inner while loop has a condition (i–). So, original value of i is 0, so that condition becomes false and later on i is equal to -1.
Then, outer loop has print instruction. -1 is printed and therefore, option 3 is correct.
Q12 – The Hue of a colour is related to its:
Luminance
Saturation
Incandescence
Wavelength
Ans – (4)
Explanation – Hue or the Color temperature is a property of light having to do with a change in color due to a change in a wavelength. Hue is the color perceived. It is the dominant color perceived by the human eye, such as red, blue, or green, and depends on the wavelength of light.
Luminance refers to color brightness.
Saturation refers to the purity level of a color.
Incandescence is light given off because of high temperature.
Q13 – “CREATE TABLE T” in SQL is an example of:
Normalization
DML
DDL
Primary key
Ans – (3)
Explanation – Data Definition Language (DDL) is used to construct and maintain the structures of databases.
The DDL statements involve CREATE TABLE specifically meant to make a new table in a database.
Other DDL operators are ALTER, DROP, TRUNCATE, and RENAME.
Q14 – An address in main memory is called:
Virtual Address
Memory Address
Logical Address
Physical Address
Ans – (4)
Explanation – An address in main memory refers to the actual location where data is stored in RAM. This is called a physical address because it represents a real, hardware-based address in a computer’s memory.
Other options –
Virtual Address – Used in virtual memory systems where programs use addresses mapped to physical addresses.
Memory Address – A general term that can refer to either virtual or physical addresses.
Logical Address – Is the address generated by CPU, which is then translated into a physical address by the Memory Management Unit (MMU).
Q15 – A system bus in which each data item is transferred during a time slice known in advance to both units source and destination is called:
MIMD
DMA
asynchronous bus
synchronous bus
Ans – (4)
Explanation – A bus is that interconnecting wire system, operating within the boundaries of a computer, used for data transfer between various units such as CPU, memory, and I/O devices.
Synchronous buses are working with a fixed time slice (i.e., a clock cycle) where the data transfer is staged by the sources and destinations at fixed times known in advance or make some arrangement memorable to both the parties in concern.
In sync with a common clock signal, it coordinates along that same bus for all devices.
Other options –
MIMD (Multiple Instruction Multiple Data) is a computer architecture that utilizes multiple processors to carry out different instructions simultaneously on various data. It doesn’t relate to bus timing.
DMA (Direct Memory Access) means transferring data from memory or to external devices without the involvement of the microprocessor. It does not refer to any style of bus.
Asynchronous Bus is distinguished by time slices whose values do not always exist but is determined using handshake signals that synchronize each other data transfer.
Q16 – What is the output of the following program?
# include <stdio.h>
# define SQR(x) (x*x)
int main()
{ int a, b = 3;
a = SQR(b + 2);
printf(“%d”, a);
return 0;
}
25
11
Garbage value
24
Ans – (2)
Explanation – Step by step analyze
Variable b = 3 and a is also a variable.
a = SQR(b + 2) // SQR(x) = (x*x)
So, it means (b + 2*b + 2)
Multiplication has higher precedence than addition, so (b + (2*b) + 2) and b = 3
Then, (3 + (2*3) + 2) = 11
Q17 – The head of a moving head disk with 200 tracks, numbered 0 to 199, has just finished a request at track 125, and currently serving a request at track 143. The queue of requests is given in the FIFO order as 86, 147, 91, 177, 94, 150, 102, 175, 130. What will be the total number of head movements required to satisfy these requests for SCAN algorithm?
259 cylinders
169 cylinders
154 cylinders
264 cylinders
Ans – (2)
Explanation – The first request in the problem follows FIFO (First-In-First-Out) order, but SCAN Scheduling Algorithm does not process requests in FIFO order.
SCAN moves in one way first-either left or right-until the end and then reverses. Here in the current example, the disk head has just finished a request at track 125 and has started servicing track 143, which means it is moving towards the right. The request queue is 86, 147, 91, 177, 94, 150, 102, 175, 130.
Multi-directional SCAN-first with the right requests – 147, 150, 175, 177. Upon completing the request at track 177, the disk head will head towards 199 and subsequently change its direction and service the left requests – 130, 102, 94, 91, and 86. Even though 86 is first in the FIFO order, it is served last because SCAN would not jump toward it immediately. It follows a systematic approach to moving in one direction before changing direction.
In the first phase, it is directed from 143 to 177 with 34 cylinders & from 199 to 177 with a further 22 cylinders onward in the right direction and then reverse direction for verification from 199 to 86 on left with 113 cylinders.
So, 34 + 22 + 113 = 169 cylinders (Option 2).
Q18 – Given as 4 GB (≈4.3 x 109 bytes) of virtual space and typical page size of 4 KB and each page table entry is 5 bytes. How many virtual pages would this imply? What is the size of whole page table?
107500 and 20480 bytes
215000 and 40960 bytes
10750 and 10240 bytes
43000 and 1024 bytes
Ans – (None)
Explanation – Virtual space = 4.3 x 109 = 4300,000,000 bytes
Page size = 4KB = 4000 bytes
Number of virtual pages = Virtual space / page size
Number of virtual pages = 1075000 pages
Page table entry = 5 bytes
Whole page table size = 1075000 x 5 = 5375000 bytes
So, the answer is 1075000 and 5375000 bytes.
Note – UGC has found an error in this question so this question is dropped.
Q19 – In Linux, where is the user password stored?
/ etc/ password
/ root/ password
/ etc/ passwd
/ root/ passwd
Ans – (3)
Explanation – In Linux-based systems, the / etc/shadow file contains user passwords, whereas / etc/passwd contains user account details.
The file contains user account information such as the username, user ID (UID), group ID (GID), home directory, and shell.
In earlier versions, Linux systems, the passwords were stored within the / etc/passwd file.
But due to security issues in modern Linux systems, while / etc/shadow has encrypted passwords, / etc/passwd contains only user details.
Q20 – Has functions are used to produce the message digests which are then encrypted with a private key to get :
Public key
Digital signature
Cipher text
Data Encryption Standard
Ans – (2)
Explanation – It’s not “Has”, its “Hash”.
In cryptographic applications, hash functions create a message digest (a fixed-size representation of data). In a digital signature, the message digest is encrypted using the sender’s private key to guarantee authenticity and integrity.
How Digital Signatures Operate
- The sender applies a hash function for the message to produce the message digest.
- The message digest is then encrypted with the sender’s private key.
- The encrypted digest is sent along with the message.
- When the receiver receives the encrypted digest, an algorithm is executed using the receiver’s public key, decrypting the original message.
- The digest, which was created anew, is then compared to ascertain its accuracy.
Q21 – Let L = {ab, aa, baa}. Which of the following strings are not in L*.
abaabaaabaa
aaaabaaaa
baaaaabaaaab
baaaaabaa
Ans – (3)
Explanation – L* means that all the strings which are formed by concatenating ab, aa and baa.
Option 1 – ab| aa| baa| ab| aa. It belongs to L*.
Option 2 – aa| aa| baa| aa. It belongs to L*.
Option 3 – baa| aa| ab| aa| aa| b. It does not belong to L*.
Option 4 – baa| aa| ab| aa
So, option 3 is the right answer.
Q22 – Let A = {a, b} and L = A*. Let x = {an bn, n > 0}. The languages L ⋃ X and X are respectively :
Not regular, Regular
Regular, Regular
Regular, Not regular
Not Regular, Not Regular
Ans – (3)
Explanation – X is not regular (proven by the pumping lemma for regular languages). This is a well-known example of a non-regular language.
L = A* is regular because it contains all strings over the alphabet {a, b}.
The union of a regular language (L) and any language (X) can be expressed as – L ∪ X
Since L already contains everything in X, joining L U X does not add anything. As L is regular, this fact implies that its union with any subset stays regular.
Thus, we conclude that L ∪ X is regular.
Option 3 is the answer.
Q23 – Which of the following symbol table implementation is best suited if access time is to be minimum?
Linear list
Search tree
Hash Table
Self-organisation list
Ans – (3)
Explanation – The symbol table that offers minimal access time is termed as the Hash Table.
Basically, A hash table provides O(1) average time complexity for searching, insertion, and deletion operations which is achieved with a hash function that distributes keys uniformly. Thus, if we use a hash table to conduct search operations, it, on average, takes constant time. The quickest among all the data structures.
Other options have higher access times –
The linear list needs to take O(n) time just to sequentially scan it.
Balanced binary search trees take O(log n).
Self-organizing lists frequently accessed elements are kept near the front, though in the worst case they still take O(n) access time.
Q24 – Consider a grammar E -> E + n | E x n | n for a sentence n + n x n, the handles in the right sentential form of the reduction are?
n, E + n and E + n x n
n, E + n and E + E x n
n, n + n and n + n x n
n, E + n and E x n
Ans – (4)
Explanation – A handle is that smallest part of an expression that can be replaced by a rule from the grammar.
A handle is that minimal unit being changed form from the equation while using given operation rules.
We are given 3 handles, E -> E + n, E -> E x n, E -> n.
First, let’s identify the smallest handle.
From E → n, n is replaced with E. So, handles in this step = n
Apply the production rule E → E × n.
n + n × n becomes n + E (by replacing n × n with E × n). So, handle here is E × n.
Now, Application of production rule E → E + n.
n + E converts into E. So, handle here is equal to E + n.
So, option 4 is the answer.
Q25 – Which data structure is typically used to implement hash table?
Linked List
Array
Binary Tree
Stack
Ans – (2)
Explanation – The hash table is a data structure that employs a hashing function to store key-value pairs. This maps keys into array indices that facilitate fast insertion, deletion, and lookup operations.
Internally, the hash table uses an array to store data at specific index locations provided by the hash function.
Under ideal circumstances, this allows insert, delete, and search operations to be executed with an average-case time complexity of O(1).
Q26 – Which collision resolution technique involves maintaining a linked list of collided keys?
Linear probing
Quadratic probing
Chaining
Double hashing
Ans – (3)
Explanation – When the number two (or more) keys have the same hash value, they try to collide-in with other keys, they approach to be at the same location in the table.
The question seeks to know which of the techniques for collision resolution stores all colliding keys in a linked list, that is, all keys that would be positioned at the same location.
Chaining uses a linked list at each spot (bucket) to hold all collided keys. Each bucket of the hash table is assigned a linked list. When several keys collide-thought of as hashing to the same bucket-they are added to a linked list in that bucket.
Other alternatives are as follows
Linear Probing – where, upon collision, the function keeps on checking the subsequent slot by moving one space at a time until an empty slot is found.
Quadratic Probing – finds the next empty spot via the quadratic function (for example, adding 1², 2², etc.).
Double Hashing – Uses a second hash function to calculate the degree of the next slot found after a collision occurs.
Q27 – Consider the following functions:
f(n) = 3n√n
g(n) = 2Гn log2n
h(n) = n!
Which of the following is true?
h(n) is O(f(n))
h(n) is O(g(n))
g(n) is not O(f(n))
f(n) is O(g(n))
Ans – (2, 3, 4)
Explanation – In g(n), there is gamma function (Гn).
Гn = ∫0infinity xn-1 e-x dx = (n-1)!
Then f(n) = 3*n√n, So, its complexity will be n√n.
g(n) = 2Гn log2n, So, its complexity will be 2(n-1)! log2n.
h(n) = n!
we know that n! > n√n, because
if n = 1, n! > n√n à 1 = 1
If n = 16, then 16! > 164 => 2*1013 > 65536
This means that f(n) < h(n) < g(n)
Option 2, 3 and 4 are correct.
Note – I copied the original question in the original paper of ugc net. But in the g(n), different authors used √ function instead of Г function. If √n is there, the g(n) will have same complexity as f(n), so in this way option 4 will be correct.
Q28 – 2-3-4 trees are B-trees of order 4. They are isometric of _________ trees.
AVL
AA
2-3
Red-Black
Ans – (4)
Explanation – A 2-3-4 tree is a self-balancing multi-way search tree in which a node can have 2, 3, or 4 children’s nodes and have 1, 2, or 3 keys. They are a special case of B-Trees (B-tree of order 4).
2-3-4 trees are basically isometric to Red-Black trees, meaning they describe the same data structure but in different forms.
A 2-node becomes a black node in a red-black tree.
A 3-node becomes a black node with one red child.
A 4-node becomes a black node with two red children.
Q29 – The average time required to search a storage location in memory and obtain its contents is called:
Access time
Latency time
Response time
Reading time
Ans – (1)
Explanation – Access time is defined as the average time taken for a given storage location in memory to be located and retrieve its contents.
This consists of memory latency (the time period consumed to access the memory location area) and transfer time (the time needed for reading data).
Access time is an important evaluation factor for accessing a memory system performance.
Why not Other Options?
Latency time – It normally refers to just the time before the transfer of data begins. It does not include the whole process of retrieval.
Response time – Commonly used in computing to refer to the complete time taken for any system to respond to the given request.
Reading time – This is not a commonly used standard technical term for memory retrieval speed.
Q30 – One of the purposes of using intermediate code in compilers is to
Make parsing and semantic analysis simpler
Improve error recovery and error reporting
Increase the chances of reusing the machine independent code optimizer in other compilers
Improve the register allocation
Ans – (3)
Explanation – Intermediate code in compilers is used primarily with the intention of making the compilation more flexible and efficient. What it does is instead of translating high-level codes directly to machine code, the compiler first translates it into an intermediate representation, independent of the target machine.
This helps achieve portability by being able to use the same intermediate code for other target machines. Machine independent optimizations can be applied to improve performance.
The intermediate code optimizer can be reused in several compilers, reducing development effort.
Q31 – The sum of minimum and maximum number of final states for a Deterministic Finite Automata (DFA) having ‘P’ state is equal to:
P
p-1
p + 1
p + 2
Ans – (3)
Explanation – A DFA must have the minimum final state is 1, because if there is no final state then there is no DFA.
The maximum final state in a ‘P’ state DFA is equal to ‘P’. Means all the states are final states.
On summing them, it is equal to P+1. Hence, option 3 is the answer.
Q32 – Test suite is consist of:
Set of defect cases
Set of boundary cases
Set of test cases
Set of nest cases
Ans – (3)
Explanation – Set of test case refers to a condition that is specific in terms of verifying the expected performance of a software application under which a software tester can ascertain its expected behavior. A Test Suite, on the other hand, brings together a collection of multiple test cases to be executed systematically.
A test suite should contain a variety of test cases that address many aspects of that software under test. These can be
1. Defect cases,
2. boundary cases, and
3. regular test cases.
Option 3 is correct.
Q33 – A multiplexes combines for 100 Kbps channels using a time slot of 2 bits. What is the bit rate?
100 Kbps
200 Kbps
40 Kbps
1000 Kbps
Ans – (Can’t tell)
Explanation – The question is wrong.
We think, the question must be this –
A multiplexer combines four 100 Kbps channels using a time slot of 2 bits. What is the bit rate?
- 100 Kbps
- 200 Kbps
- 400 Kbps
- 1000 Kbps
In this question, a multiplexer combines four channels transmitting at 100 Kbps each.
Each channel transmits 2 bits during a time-slot.
To arrive at the total bit rate, the number of time slots sent in one second needs to be calculated first.
Since each is sending at 100,000 bits, which means 50,000 time slots are sent in one second due to two bits per channel being sent in one time-slot.
Each time slot consists of 8 bits in total (as we have 4 channels, and each is sending 2 bits). It follows that the total bit rate is 50,000 x 8, which equals 400,000 bps, which is 400 Kbps. In this way, the answer is that the information rate here is probably 400 Kbps.
Q34 – Which of the following is not a field in TCP header?
Sequence Number
Checksum
Fragmentation offset
Window Size
Ans – (3)
Explanation – The TCP header does not include a Fragment Offset field. The responsibility of this field belongs to the IP header and not TCP.
Thus, answer option (3) is correct considering the Fragment Offset.
Q35 – In “bit stuffing”, each frame begins and ends with a bit pattern in hexadecimal?
Ox8C
Ox6F
OxFF
Ox7E
Ans – (4)
Explanation – Bit stuffing uses some sequences of bits (sometimes called flags) to indicate the beginning and the end of a frame in the transmission of data.
Each frame begins and ends with a specific pattern of bits. Usually, that form, in binary, is
Binary – 0111110
Hexadecimal – 0x7E
With a view to avoiding any ambiguities that would occur if the same flag sequence should appear in the raw data, one other bit, normally a 0, is stuffed after five consecutive ones (11111). This is done to avoid the risk of misidentification of frames by the receiver.
Thus, the frame begins and ends with hexadecimal 0x7E.
Q36 – Level-0 DFD is also called as:
Use Case diagram
Sequence diagram
Context diagram
Prototype diagram
Ans – (3)
Explanation – A Data Flow Diagram(DFD) is an illustration showing how data flows through a system. It contains different levels with varying detail of expression.
Level 0 DFD – Sometimes called a Context Diagram represents the entire system as a single process. It shows the external entities which are users and other systems and their interaction with the system. No internal process details.
An example of a very simple flow is that of a library management system wherein the “Library System” interacts with “Students” and “Librarians”
Level 1 DFD – This level breaks the single process mentioned in Level 0 into the main sub-processes and indicates major data flows between these processes.
Example – Issue Books; Return Books
Level 2 DFD – More particular information concerning each Level 1 process is supplied. Shows exact data storage and interactions.
An example is, verify student’s ID and check book availability for Issue books.
Level 3 DFD – Further breakdown of Level 2 subprocesses are required. This is usually required in case of a complex system.
Example – Verify student’s eligibility.
Q37 – What is the generic structure of Multi Agent System (MAS) ?
Single agent with multiple objectives
Multiagents with a single objectives
Multiagents with diverse objectives and communication abilities
Multiagent with two objectives
Ans – (3)
Explanation – A multi-agent system represents a system in which agents cooperate together toward a goal for which they have different objectives, yet they communicate and coordinate with each other. These agents can be either independent or cooperative; levels of cooperation vary with respect to the environment shared by the agents for the achievement of separate or common objectives.
Q38 – A __________ point of fuzzy set A is a point x ԑ X at which μA(x) = 0.5.
Core
Support
Crossover
α – cut
Ans – (3)
Explanation – Assume you have a fuzzy set having an element x, which is assigned a degree of membership from 0 to 1 according to how much it belongs to the set. The meaning of the scores can be summarized as follows –
1 – The element completely belongs to the set.
0 – The element does not belong in any way.
Between 0 and 1 – The element belongs partially.
Now the crossover point is that one special point where the membership score is exactly 0.5. Thus, an element is halfway in and halfway out of the set.
Core – The score that is 1 (fully belonging to the set).
Support – A set of all points with scores more than 0.
α–cut – This is a set of all points where the score is at least α.
Q39 – In a genetic algorithm optimization problem, the fitness function is defined as F(x) = x2 – 4x + 4
Given a population of four individuals with values of x: {1.5, 2.0, 3.0, 4.5}
What is the fitness value of the individual that will be selected as the parent for reproduction in one generation?
2.25
6.0
0.0
6.25
Ans – (4)
Explanation – A function F(x) = x2 − 4x + 4 indicates how “fit” or “good” an individual is within the framework of optimization problems.
The function F(x) must be evaluated for every x in order to scale their fitness values. Higher fitness values mean a greater chance of being selected for mating in Genetic Algorithms.
A population of four individuals with values of x: {1.5, 2.0, 3.0, 4.5}
F(1.5) = (1.5)2 – 4(1.5) + 4 = 2.25 – 6.0 + 4 = 0.25
F(2.0) = (2.0)2 – 4(2.0) + 4 = 4.0 – 8.0 + 4 = 0.0
F(3.0) = (3.0)2 – 4(3.0) + 4 = 9.0 – 12 + 4 = 1.0
F(4.5) = (4.5)2 – 4(4.5) + 4 = 20.25 + 18 + 4 = 6.25 (highest)
Thus, x = 4.5 with fitness value 6.25 will be selected as the parent.
Q40 – In a feed forward neural network with the following specifications:
Input layer has 4 neurons, hidden layer has 3 neurons and output layer has 2 neurons using the sigmoid activation function for given input values [0.5, 0.8, 0.2, 0.6] as well as the initial weights for the connections.
Input layer to hidden layer weights
W1: [0.1, 0.3, 0.5, 0.2]
W2: [0.2, 0.4, 0.6, 0.2]
W3: [0.3, 0.5, 0.7, 0.2]
Hidden layer to output layer weights
W4: [0.4, 0.1, 0.3]
W5: [0.5, 0.2, 0.4]
What is the output of the output layer when the given input values are passed through neural network? Round the answer to two decimal places:
[0.62, 0.68]
[0.72, 0.78]
[0.82, 0.88]
[0.92, 0.98]
Ans – (1)
Explanation – The question asks what will be the final output of the neural network after passing the given inputs through the hidden layer and then to the output layer.
We need to calculate the weighted sum at each layer, apply the sigmoid activation function, and find the final output values at the output layer.
Finally, we round the result to two decimal places.
Input values – [0.5, 0.8, 0.2, 0.6]
The weighted sum (net input) for each hidden neuron is
W1: [0.1, 0.3, 0.5, 0.2]
Hidden Neuron 1 (h1) = 0.5*0.1 + 0.8*0.3 + 0.2*0.5 + 0.6*0.2
= 0.05 + 0.24 + 0.10 + 0.12 = 0.51
W2: [0.2, 0.4, 0.6, 0.2]
Hidden Neuron 2 (h2) = 0.5*0.2 + 0.8*0.4 + 0.2*0.6 + 0.6*0.2
= 0.10 + 0.32 + 0.12 + 0.12 = 0.66
W3: [0.3, 0.5, 0.7, 0.2]
Hidden Neuron 3 (h3) = 0.5*0.3 + 0.8*0.5 + 0.2*0.7 + 0.6*0.2
= 0.15 + 0.40 + 0.14 + 0.12 = 0.81
We apply sigmoid activation function – σ(x) = 1/(1 + e-x)
For h1 = 0.51, σ(0.51) = 1/(1 + e-0.51) = 0.6248
For h2 = 0.51, σ(0.66) = 1/(1 + e-0.66) = 0.6592
For h3 = 0.51, σ(0.81) = 1/(1 + e-0.81) = 0.6921
The weighted sum for each output neuron is
W4: [0.4, 0.1, 0.3]
Output Neuron 1 (O1) = 0.6248*0.4 + 0.6592*0.1 + 0.6921*0.3
= 0.24992 + 0.06592 + 0.2076 = 0.5234
W5: [0.5, 0.2, 0.4]
Output Neuron 2 (O2) = 0.6248*0.5 + 0.6592*0.2 + 0.6921*0.4
= 0.3124 + 0.1318 + 0.2768 = 0.7210
Now, we apply sigmoid activation function – σ(x) = 1/(1 + e-x)
For O1 = 0.5234, σ(0.5234) = 1/(1 + e-0.5234) = 0.6279
For O2 = 0.7210, σ(0.7210) = 1/(1 + e-0.7210) = 0.6728
Option 1 is right [0.62, 0.68]
Q41 – If universe of disclosure are all real numbers, then which of the following are true?
(a) ꓱx ꓯy (x + y = y)
(b) ꓯx ꓯy(((x ≥ 0) Λ (y < 0)) à (x – y > 0))
(c) ꓱx ꓱy(((x ≤ 0) Λ (y ≤ 0)) Λ (x – y > 0))
(d) ꓯx ꓯy(((x ≠ 0) Λ (y ≠ 0)) ↔ (xy ≠ 0))
Choose the correct answer from the options given below:
(a) and (b) only
(a), (c) and (d) only
(a), (c) and (d) only
(a), (b), (c) and (d) only
Ans – (4)
Explanation – ꓱx meaning is “there exist a number x”, and ꓯx meaning is “for all x”.
(a) – ꓱx ꓯy (x + y = y)
This means there exists some real number x, such that for all y, the equation x + y = y holds. When x = 0, then this option is true.
(b) – ꓯx ꓯy(((x ≥ 0) Λ (y < 0)) à (x – y > 0))
This means for all real numbers x and y, if x is non-negative and y is negative, then x – y > 0.
So, x – (-y) is always positive, hence this option is true.
(c) – ꓱx ꓱy(((x ≤ 0) Λ (y ≤ 0)) Λ (x – y > 0))
This means that there exist real numbers x and y such that if x is negative, and y is also negative, then x – y > 0
If we take x = – 2, y = -3, then (-2) – (-3) > 0
(d) – ꓯx ꓯy(((x ≠ 0) Λ (y ≠ 0)) ↔ (xy ≠ 0))
This means that for all x and y, if x is non-zero and y is non-zero then xy is non-zero and vice-versa.
Option 4 is correct.
Q42 – If the universe of disclosure is set of integers, then which of the followings are TRUE?
(a) ꓯn ꓱm (n2 < m)
(b) ꓱn ꓯm (n < m2)
(c) ꓱn ꓱm (nm = m)
(d) ꓱn ꓱm (n2 + m2 = 6)
(e) ꓱn ꓱm (n + m = 4 Λ n – m = 1)
Choose the correct answer from the options given below
(a), (b) and (c) only
(b) and (c) only
(c), (d) and (e) only
(c) and (e) only
Ans – (2)
Explanation – Universe of discourse – Set of Integers
(a) ꓯn ꓱm (n2 < m) – For every integer n, there exists an integer m, such that n2 < m.
Example – If n = 4, then n2 = 16. We can take m = 17 which satisfies 16 < 17. Therefore, it is correct.
(b) ꓱn ꓯm (n < m2) – There exists some integer n such that for every integer m, n < m2. This statement is true.
Example – Let n = -1, then for every integer m, this expression n<m2 is true.
Let’s say m = 0, then n < m2 → -1 < 0
Let’s say m = -1, then n < m2 → -1 < 1
Let’s say m = 1, then n < m2 → -1 < 1
Let’s say m = -2, then n < m2 → -1 < 4
(c) ꓱn ꓱm (nm = m) – There exist integers n and m such that nm = m.
Let’s say n = 1 and m = any integer, then nm is that “any integer”, which satisfies the equation. Hence this statement is correct.
(d) ꓱn ꓱm (n2 + m2 = 6) – There exist integers n and m such that n2 + m2 = 6.
This is not correct. Because on squaring the two integers, the difference is not 6.
(-2)2 = 4, (-1)2 = 1, 02 = 0, 12 = 1, 22 = 4, 32 = 9, 42 = 16, 52 = 25
There are not two integers, who’s on squaring, get the difference 6.
(e) ꓱn ꓱm (n + m = 4 Λ n – m = 1) – There exist integers n and m such that n + m = 4 AND n – m = 1.
So, we have to find n and m where n + m = 4 and also n – m = 1.
Solving the equation, we get n = 2.5 and m = 1.5, which are not the integer. So, this statement is incorrect.
Q43 – If N2 = N x N, N is set of natural numbers and R is relation on N2, s.t. R C N2 x N2 i.e. <x, y> R <u, v> ↔ xv = yu, then which of the following are TRUE?
(a) Reflexive
(b) Symmetric
(c) Transitive
(d) Asymmetric
Choose the correct answer from the options given below:
(a) and (b) only
(b) and (c) only
(a), (c) and (d) only
(a), (b) and (c) only
Ans – (4)
Explanation – N is the set of natural numbers, means 1, 2, 3, 4, …
R is a relation on N2 where, <x, y> R <u, v> if and only if xv = yu
(a) Reflexive – A relation R is reflexive if each pair is related to itself.
In our question, (x, y) R (u, v) iff xv = yu
For reflexivity <x, y> R <x, y> that means x.y = y.x
Since x = u and y = v, it means xv = yu
So, relation R is reflexive.
(b) Symmetric – A relation R is symmetric if (x, y)R(u, v) holds, then (u, v)R(x, y) holds.
(x, y)R(u, v) => xv = yu, and
(u, v)R(x, y) => uy = vx
It is same xv = vx = yu = uy
So, relation is symmetric.
(c) Transitive – A relation R is transitive if (x, y)R(u, v) holds, then (u, v)R(p, q) also must hold.
(x, y)R(u, v) => xv = yu
(u, v)R(p, q) => uq = vp
We have to prove xq = yp
- xv = yu
- (xv)*q = (yu)*q
- Also, uq = vp
- y*(uq) = y*(vp)
- xvq = yvp [v cancel from both sides]
- xq = yp
(d) Asymmetric – we proved that relation R is symmetric. So, R is not asymmetric.
Option 4 is the answer.
Q44 – The interface(s) that provide(s) I/O transfer of data directly to and from the memory unit peripheral is/are termed as:
(a) DMA (Direct Memory Access)
(b) IOP (Input-Output Processor)
(c) Serial Interface
(d) Parallel Interface
Choose the correct answer from the options given below
(a) only
(b) only
(a) and (b) only
(c) and (d) only
Ans – (3)
Explanation – The question asks about which interfaces allow data transfer directly between memory units and peripheral devices.
Direct Memory Access (DMA) facilitates direct transfer of data between memory and peripherals, without CPU involvement, thereby increasing performance since the CPU can engage in other tasks while data is transferred in the background.
Input-output processors (IOP) manage any I/O operation independently of the CPU and are in communication with memory and peripheral devices.
Serial interfaces (For example – USB, RS-232) do not directly access memory. They need CPU interaction.
Parallel interfaces (For example – Most printers) are such that they send data in a parallel dig. They are unable to create direct memory access which essentially requires CPU intervention.
Q45 – Which of the following(s) are main memory?
(a) Virtual Memory
(b) Cache memory
(c) RAM
(d) SSD
Choose the correct answer from the options given below:
(a) and (c) only
(b) and (c) only
(c) and (d) only
(a), (b) and (c) only
Ans – (2)
Explanation – Main memory, sometimes referred to as primary storage, is the working memory of the computer, where the CPU keeps the data and program instructions currently in use. It is volatile, which means that data residing in RAM will be lost when the computer is powered off.
Types of Main Memory
RAM – It stores the operating system, applications, and data currently being used by the computer. Fast and directly accessible by the CPU.
Cache Memory – It holds copies of those data most frequently accessed from the main RAM. It is extremely fast and placed near the CPU. Helps reduce the time to access data from the main memory.
Virtual memory is a technique that extends RAM and SSD (Solid State Drive) is a secondary memory that is non-volatile.
Q46 – Which of the following are tautology?
A. (P → (P Λ Q)) → (P → Q)
B. ((P → Q) → Q) → (P V Q)
C. ((P V ¬P) → Q) → (P V ¬P) → R)
D. (Q → (P Λ ¬P)) → (R → (P Λ ¬P))
A only
B only
A and B only
C and D only
Ans – (3)
Explanation –
A. (P → (P Λ Q)) → (P → Q)
- (¬ P v (P ∧ Q)) → (P → Q)
- (¬ P v P ∧ ¬ P v Q) → (P → Q)
- (¬ P v Q) → (P → Q)
- (¬ P v Q) → (¬ P v Q)
If x → x, then it’s a tautology.
.
B. ((P → Q) → Q) → (P V Q)
- ((¬ P v Q) → Q) → (P ∨ Q)
- (¬ (¬ P v Q) v Q) → (P ∨ Q)
- (P ∧ ¬ Q) v Q) → (P ∨ Q)
- (P v Q ∧ ¬ Q v Q) → (P ∨ Q)
- (P v Q) → (P ∨ Q)
If x → x, then it’s a tautology
Alternative way
A.
P | Q | PΛQ | P→Q | P→(PΛQ) | (P→(PΛQ)) → (P→Q) |
0 | 0 | 0 | 1 | 1 | 1 |
0 | 1 | 0 | 1 | 1 | 1 |
1 | 0 | 0 | 0 | 0 | 1 |
1 | 1 | 1 | 1 | 1 | 1 |
B.
P | Q | P→Q | (P→Q)→Q | PVQ | ((P→Q)→Q) → (PVQ) |
0 | 0 | 1 | 0 | 0 | 1 |
0 | 1 | 1 | 1 | 1 | 1 |
1 | 0 | 0 | 1 | 1 | 1 |
1 | 1 | 1 | 1 | 1 | 1 |
Q47 – Consider the three points P1(1, 2, 0), P2(3, 6, 20) and P3(2, 4, 6) and a view point C(0, 0, -10).
Choose the correct options.
(a) P1 obscure P2, if viewed from C.
(b) P2 obscure P1, if viewed from C.
(c) P3 does not obscure P1, if viewed from C.
(d) P2 does not obscure P3, if viewed from C.
Choose the correct answer from the options given below:
(a), (b) and (c) only
(a), (c) and (d) only
(b), (c) and (d) only
(a), (b) and (d) only
Ans – (2)
Explanation – Obscure means to block the view or to hide anything from the sight.
Points (x, y) of C, P1, P3 and P2 is (0, 0), (1, 2), (2, 4) and (3, 6) respectively. Means y is just double the x, so in that graph C is the first point, then second point is P1, then third point is P3, and then P2 is the last one.
The z point of C, P1, P3 and P2 is -10, 0, 6 and 20.
(a) P1 obscure P2, if viewed from C. – Correct (C -> P1 -> P2)
(b) P2 obscure P1, if viewed from C. – Incorrect (C -> P1 -> P2)
(c) P3 does not obscure P1, if viewed from C. – Correct (C -> P1 -> P3)
(d) P2 does not obscure P3, if viewed from C. – Correct (C -> P3 -> P3).
Q48 – Which of the statement are CORRECT?
(a) Constructors are invoked automatically when the objects are created.
(b) Constructors do not have return types, not even void and therefore they cannot return values.
(c) Constructors cannot be inherited though a derived class can call the base class constructors.
(d) Constructors can be declared as virtual
Choose the correct answer from the options given below:
(a), (b) and (d) only
(a), (b) and (c) only
(b), (c) and (d) only
(a), (c) and (d) only
Ans – (2)
Explanation – (a) It has been established that a constructor, which is a special member function in OOP, initializes an object when an instance of a class or object of a class is created. Hence, this statement is correct.
(b) In programming languages such as C++ and Java, a constructor is a special function that initializes an object when it is created, and it does not return a value. Hence it is not like the normal functions.
(c) This is again a correct statement. Constructors can never be inherited by derived classes, but derived classes can explicitly call their base class constructors using either super() (in Java) or BaseClassName() (in C++).
(d) A constructor can never be declared virtual, as they are used for initializing an object in C++. In fact, the existence of virtual functions depends on an object which is already initialized. So, this statement is wrong.
Q49 – Which one of the following are correct?
(a) Granularity is the size of data item in a database.
(b) Two operations in a schedule are said to be conflict if they belong to same transaction.
(c) Two schedulers are said to be conflict equivalent if the order of any two conflicting operations is the same in both schedules.
(d) Write operations which are performed without performing the write operation are known as Blind Writes.
Choose the correct answer from the options given below:
(a) and (b) only
(a), (b) and (c) only
(a), (b) and (d) only
(b) and (c) only
Ans – (2)
Explanation – (a) – Granularity refers to the size or level of detail in which data is processed, stored, or managed. It defines how small or large a unit of data is when being accessed or controlled.
In databases, granularity defines how much data is treated as a single unit for locking, concurrency control, and transactions.
Conflicting & Non-Conflicting Operations
Two operations from the same transaction always conflict. Whether they are read-read operations or read-write operations.
Two operations from the different transactions are conflicting if
- They operate on the same database element.
- One of the operations is write.
According to this –https://www.cs.emory.edu/~cheung/Courses/554/Syllabus/7-serializability/conflict.html
(b) – In the context of database transactions, two operations are considered conflicting if they are from the same transaction. Then the statement is correct.
(c) – Correct because conflict-equivalent schedules maintain the same order of conflicting operations, ensuring the same final result.
(d) – Write operations which are performed without performing the read operation are known as blind writes. But it says “without performing the write operation”, is absolutely wrong.
So, option 2 is correct.
Q50 – Which of the following is/are NOT CORRECT statement?
(a) The first record in each block of the data file is known as actor record.
(b) Dense index has index entries for every search key value in the data file.
(c) Searching is harder in the B+ tree than B- tree as the all external nodes linked to each other.
(d) In extensible hashing the size of directory is just an array of 2d-1 where d is global depth.
Choose the correct answer from the options given below:
(a), (b) and (c) only
(a), (c) and (d) only
(a), (b) and (d) only
(a), (b), (c) and (d) only
Ans – (2)
Explanation – (a) There is no concept of an “actor record” in file organization or indexing.
(b) An index in a database is similar to a listing of contents in a book since that enables one to quickly locate data without scanning the entire file.
There are two major types of indexes
Dense Index is having an entry for each and every search-key value in the data file.
This provides faster look-ups since a database record is indexed.
Sparse Index will have an entry for some records, and not all.
This will save space but it will take longer to find the data since additional searching inside the data blocks is required.
Hence the statement written is correct, but the question asks NOT CORRECT, so this is not the answer.
(c) A B+ tree features all keys being present only in the leaf nodes, which contain spans between them to speed up range queries; hence searching in a B+ tree is faster.
A B-tree features keys to exist in both internal nodes and leaf nodes which will complicate searching just a little bit. This is a NOT CORRECT statement.
(d) The size of the directory in extensible hashing is 2d, where d is the global depth. Hence, this statement is NOT CORRECT.
So, answer will be option number 2.
Q51 – Which of the following statements is/are NOT CORRECT about NUMA?
(a) LOAD and STORE instructions are used to access remote memory.
(b) There is a single address space visible to all CPU.
(c) Access to local memory is slower than access to remote memory.
(d) When the access time to remote memory is hidden, the system is called NC-NUMA.
(e) IN CC-NUMA, coherent caches are present.
Choose the correct answer from the options given below:
(a) and (c) only
(b) and (d) only
(a) and (e) only
(c) and (d) only
Ans – (4)
Explanation – NUMA is an acronym for Non-Uniform Memory Access indicating memory architecture to fit multiprocessor systems where each CPU has its own little local memory, but can always access memory in possession of other processors. However, remote memory accesses are slower than local memory accesses.
In classic Symmetric Multiprocessing systems, all processors accessed a common pool of memory, but this could lead to congestion and significantly reduce performance. NUMA improved this by partitioning memory onto processors. The operating system always tried to keep together processes and data that behaved like hot spots, therefore reducing remote memory access.
Types of NUMA
CC-NUMA (Cache-Coherent NUMA) – This works by maintaining cache coherence: therefore, all CPUs see the changes in memory.
NC-NUMA (Non-Cache-Coherent NUMA) – Does not maintain cache coherence; rather, the software must manage it.
Option (a) – In NUMA, CPUs can access both local and remote memory using standard LOAD and STORE instructions.
Option (b) – NUMA maintains a shared address space such that any CPU can access memory; however, access times are varied.
Option (c) – Wrong, because local memory is faster.
Option (d) – Wrong, because there is no hidden access time here.
Option (e) – (Cache-Coherent NUMA ) uses cache coherence mechanisms to keep data consistent among different processors.
Q52 – Indexed/Grouped allocation is useful as
(a) It supports both sequential and direct access.
(b) Entire block is available for data.
(c) It does not require lots of space for keeping pointers.
(d) No external fragmentation.
Choose the correct answer from the options given below:
(a) only
(b) and (c) only
(b) only
(a), (b) and (d) only
Ans – (4)
Explanation – Indexed allocation stores files in such a way that an index block keeps track of all disk blocks allocated for the file. This prevents fragmentation and enables block-level access to any position in the file.
Indexed allocation enables sequential access (reading blocks in order) as well as direct access, with the pointers to each block in the index block allowing for direct lookup.
In indexed allocation, the index point is stored separately from the actual block, while part of the block stores a pointer to the next block in linked allocation.
This way, external fragmentation can be avoided because whenever a block is allocated, it is done so individually and need not be organized in a contiguous manner.
Indexed allocation does require additional space for splitting the index block. For very large files, this could mean an additional overhead of several index blocks.
Q53 – Which of the following statement are correct?
(a) A process always check state of currently executing process to enter critical schema.
(b) Spin locks uses busy waiting.
(c) Periodically testing a variable until some value appear is known as busy waiting.
(d) Critical region is a part of program, where shared memory is kept.
(e) Printer daemon, continuously checks to see if there are any file to be printed.
Choose the correct answer from the options given below:
(a) and (b) only
(b) and (c) only
(b) and (d) only
(b) and (e) only
Ans – (3)
Explanation – (a) is wrong, because if multiple processes want to access a shared resource (e.g., a printer), they don’t check which process is running. Instead, they check a lock or flag to see if the resource is available to determine if a process can enter the critical section.
(b) is correct. Spin lock is a locking mechanism used in multi-threading and multi-processing to avoid concurrent access by multiple processes and threads to shared resources.
When a process (or thread) wants access to a shared resource, it checks whether it is available. If the resource is being used, the process spins on a loop until it becomes available. As soon as the resource is free, the process can enter into the critical section and use the resource.
Consider a public toilet that operates with just one key. You reach the toilet, but it’s occupied. Instead of leaving and returning after some time, you decide to keep knocking at the door every second. The moment the occupant exits, you quickly push the door and enter before anyone else does. That’s busy waiting.
(c) statement uses busy waiting. You are thinking that this statement is correct, but it is not. The system does not “periodically”, it checks continuously without pausing.
(d) A critical region (or critical section) is a part of a program where a shared resource (like shared memory, a file, or a printer) is accessed. This is correct.
(e) A printer daemon is a background process that manages printing jobs. However, it does not check for new print jobs all the time (busy waiting). A printer daemon that kept busy waiting all the time might be wasting CPU cycles. It is efficient because it just waits for a signal from the system that a print job has been added. Therefore, this statement is wrong.
Q54 – Three address codes can be represented in special structures known as:
(A) Quadruples
(B) Triples
(C) Patterns
(D) Indirect Triples
Choose the correct answer from the options given below :
(A) and (B) Only
(A), (B) and (D) Only
(B) and (C) Only
(B), (C) and (D) Only
Ans – (2)
Explanation – Three-address codes can be represented using certain structures that help in organizing an intermediate representation of code inside a compiler. The structures are named Quadruples, Triples, and Indirect Triples.
(A) Quadruples – This has four fields operator, argument1, argument2, and result, which helps in organizing expressions and statements in a neat and efficient format.
(B) Triples – Unlike quadruples, this does not provide a separate field for storing the result. Instead, the reference to the results uses indices.
(D) Indirect Triples – A variation of the triples is one in which pointers are used to reference statements, easing the process of reordering the code.
Q55 – Which of the statement is/are CORRECT ?
(A) Moore and Mealy machines are finite state machines with output capabilities.
(B) Any given Moore machine has an equivalent Mealy machine.
(C) Any given Mealy machine has an equivalent Moore machine.
(D) Moore machine is not a finite state machine.
Choose the correct answer from the options given below :
(A) and (B) Only
(A), (B) and (C) Only
(B) and (D) Only
(A), (B) and (D) Only
Ans – (2)
Explanation – The Moore and Mealy machines are finite-state machines with outputs capability.
A Moore machine produces output based solely on its current state and the Mealy machine produces output depending on state and input symbols. generating output is their property. Thus, both machines are an FSM.
Also, every Moore machine has an equivalent Mealy machine, as in the case of mapping the transitions of inputs onto the state-dependent output. Also, every Mealy machine is actually able to be converted into an equivalent Moore machine. But it is wrong to state that a Moore machine is not an FSM, as Moore machines are a FSMs. The correct answer is option 2.
Q56 – The statement P(x): “ x=x2 “. If the universe of disclosure consists of integers, what are the following have truth values :
(A) P(0)
(B) P(1)
(C) P(2)
(D) Ǝx P(x)
(E) ∀x P(x)
Choose the correct answer from the options given below:
(A), (B) and (E) Only
(A), (B) and (C) Only
(A), (B) and (D) Only
(B), (C) and (D) Only
Ans – (3)
Explanation – P(x): x = x²
This means that x must be equal to its square (x²).
(A) P(0): 0 = 0² Correct
(B) P(1): 1 = 1² Correct
(C) P(2): 2 = 2² => 2 = 4 Incorrect
(D) There exists at least one x such that x = x². So, this is also correct
(E) For all x, x = x² Incorrect.
Option 3 is the answer.
Q57 – Which of the following statement are truth statements if universe of disclosure is set of integers:
(A) ∀n (n2 >= 0)
(B) ∃n (n2 = 2)
(C) ∀n (n2 >= n)
(D) ∃n (n2 < 0)
Choose the correct answer from the options given below :
(A) and (B) Only
(B) and (C) Only
(C) and (D) Only
(A) and (C) Only
Ans – (4)
Explanation – (A) ∀n (n2 >= 0) is true because for all integers, n2 >= 0,
If n = 0, then it is true
If n = 1, then it is true.
(B) ∃n (n2 = 2) is false because this means there exists an integer such that n2 = 2, which is not correct. Square of an integer is (0, 1, 4, 9, …)
(C) ∀n (n2 >= n) is true because this means that all integer square must be greater than or equal to that integer.
If n = 0, 0 >= 0, then it is true
If n = 1, 1 >= 1, then it is true.
If n = -1, 1 >= 1, then it is true.
If n = 2, 4 >= 2, then it is true.
(D) ∃n (n2 < 0) is false because this means there exists an integer such that n2 < 0.
If n = 0, 0 < 0 which is not true.
Q58 – Which of the following graphs are trees?
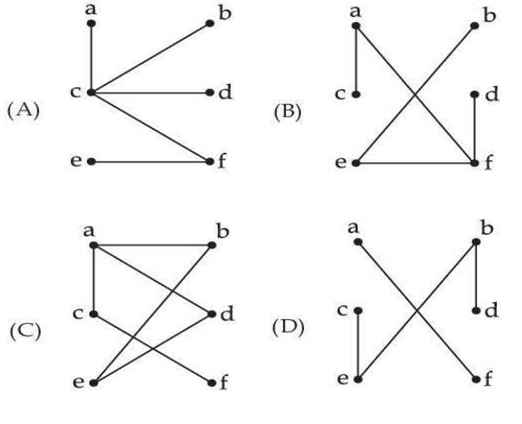
(a) and (b) only
(a), (b) and (d) only
(a) and (d) only
(a), (b), (c) and (d) only
Ans – (1)
Explanation –
(a) and (b) are trees.
(c) is not a tree because adeb form a graph
(d) It is not hierarchical so that’s why not a tree.
Q59 – Which of the following are examples of CSMA channel sensing methods?
(a) 1-persistent
(b) 2-persistent
(c) p-persistent
(d) o-persistent
Choose the correct answer from the options given below
(a), (b) and (d) only
(a), (c) and (d) only
(b), (c) and (d) only
(a), (b) and (c) only
Ans – (2)
Explanation – Types of CSMA channel sensing mode
1-Persistent – It listens to the shared channel first and sends data immediately if the channel is free. If not, it will have to wait and, by observing the channel continuously, transmit the frames as soon as it finds it free. Thus, it’s an aggressive transmission algorithm.
Non-Persistent – It first checks the channel for data transmission. If the channel is idle, the node will transmit data immediately. If it is busy, however, the station must wait for some random time (not continuously), and once it detects that the channel is again free, transmission occurs.
P-Persistent – This is an amalgamation of the 1-Persistent and Non-Persistent modes. Each of the nodes senses the channel in 1-Persistent mode. If it is sensed that the channel is unoccupied, the node transmits the frame with a P probability. If the data is not transmitted, then, after waiting first for a random period of time (observed with the (q = 1-p probability)), the frame will attempt transmission again with the start of the next time slot.
O-Persistent – A supervisory node will order every node to transmit during its designated time slot when the medium becomes idle.
So, the 2nd option is correct.
Q60 – The selection of spiral model based on characteristics of requirements
(a) Are requirements easily understandable and defined?
(b) Do we change requirements quite often?
(c) Can we define requirements early in the cycle?
(d) Requirements are indicating a complex to be built
Choose the correct answer from the given options
(c) only
(b) only
(b) and (d) only
(a) and (c) only
Ans – (3)
Explanation – The Spiral Model is the recommended option in software development when projects face high levels of risk and complexity. Further, it combines the iterative nature of the Prototyping Model with the systematic aspects of the Waterfall model while focusing on a risk analysis in each phase.
The Spiral Model is a perfect choice when
- The requirements keep changing.
- The stakeholders or clients are not able to finalize the requirements in the initial process.
- The project will take several iterations or refinements, so it means (b).
The Spiral Model is good when
- In case of higher complexity and risk.
- Whenever new technologies and methodologies are incorporated.
- Whenever the assessment and evaluation of risks take place repeatedly throughout the entire project. This means (d) is validated.
Option (a)
The Spiral Model is not recommended when clear and well-defined requirements at the start of the project exist. Thus, a better choice would be the Waterfall Model or V-Model.
Option (c)
If requirements are known upfront, go with Waterfall. However, Spiral is for projects where requirements evolve through the length a little.
Q61 – The work done by UDP is/are:
(A) Congestion control
(B) Flow control
(C) Retransmission
(D) Segments transmission
Choose the correct answer from the options given below :
(A) and (D) Only
(C) Only
(D) Only
(B) and (C) Only
Ans – (3)
Explanation – UDP is a transport protocol that provides for transmission of datagram segments in the order and delivery specified by destination but not guaranteed. Each packet is sent without waiting for an acknowledgment.
(A) Congestion control – It does not offer any congestion control, packets are sarcastically sent regardless of congestion.
(B) Flow control – UDP lacks flow-control capabilities that would prevent the sender from flooding the receiver with packets.
(C) Retransmission – It is not an obligation for UDP to ensure delivery, rather, it will silently drop a packet and move on to transmit the next one.
Q62 – Which of the following statement/s is/are NOT CORRECT?
(a) OSPF is based on distance-vector routing protocol.
(b) Both link-state and distance-vector routing are based on the least cost goal.
(c) BGP4 is based on the path-vector algorithm.
(d) The three-node instability can be avoided using split horizon combined with poison reverse.
(e) RIP is based on link state algorithm.
Choose the correct answer from the options given below:
(a), (d) and (e) only
(a) and (b) only
(b) and (c) only
(b), (c) and (e) only
Ans – (1)
Explanation – Routing refers to the process of finding the best path for data to travel from one computer (or network device) to another computer or network device through a network, like the internet.
Static Routing
The path is manually set by the network administrator.
Dynamic Routing
Automatically updates/learn/upgrades the best path based on change in the network.
By the following routing protocol (OSPF, RIP, BGP).
Protocol | Type |
|
OSPF (Open Shortest Path First) | Link-State Routing Protocol | It finds the shortest path using the Dijkstra algorithm. |
RIP (Routing Information Protocol) | Distance-Vector Routing Protocol | Each router tells its neighbours how far destinations are using hop count (number of routers to cross). |
BGP (Border Gateway Protocol) | Path-Vector Routing Protocol | Instead of finding the shortest path, it chooses the most stable and policy-based path. |
(a) OSPF is based on distance-vector routing protocol. – Not Correct
(b) Both link-state and distance-vector routing are based on the least cost goal. – Correct
Because it finds least cost or shortest path between the nodes in a network.
(c) BGP4 is based on the path-vector algorithm. – Correct
(d) The three-node instability can be avoided using split horizon combined with poison reverse. – Not correct
What this means is – Although split horizon and poison reverse technique help reduce routing loops, three-node instability associated with distance-vector routing is not completely addressed.
Distance vector routing updates take time to converge, which is why there is a three-node instability.
(e) RIP is based on link state algorithm. – Not Correct
Hence, option 1 is the answer.
Q63 – Which of the following statement/s are CORRECT ?
(A) NRZ is a bipolar scheme in which the positive voltage define bit is 0 (zero).
(B) NRZ-L and NRZ-I both have an average signal rate of N/2.
(C) The idea of RZ and NRZ-L are combined into Manchester scheme.
(D) NRZ-L and NRZ-I both have DC component problems.
(E) The minimum bandwidth of Manchester and differential Manchester is 3 times that of NRZ.
Choose the correct answer from the options given below :
(A), (B) and (C) Only
(A), (C), (D) and (E) Only
(B), (C) and (D) Only
(A), (B), (C) and (E) Only
Ans – (3)
Explanation – The first statement (A), that NRZ is a bipolar scheme-where a positive voltage volume is said to represent bit 0-is not true. NRZ is either a unipolar or a polar scheme, and not bipolar. In NRZ-L, voltage levels directly represent bits. In NRZ-I, a transition occurs on bit 1.
The second statement (B) is correct. Both NRZ-L and NRZ-I average a signal rate of N/2, because they do not change state at every bit, the baud rate is half the data rate.
The third statement (C) is also correct, as Manchester encoding combines features of RZ and NRZ-L, in that there is some transition per each method thereby facilitating synchronization.
The fourth statement (D) is correct, that both NRZ-L and NRZ-I have DC-component problems because of long strings of constant voltage levels that can lead to synchronization problems.
The fifth statement (E) is incorrect because Manchester and Differential Manchester encoding require twice the bandwidth of NRZ, rather than three times, because every bit has a transition. Therefore, answer 3 is a correct.
Q64 – Which of the following are commonly used parsing techniques in NLP (Natural Language Processing) for the syntactical analysis.
(a) Top-down parsing
(b) Bottom-up parsing
(c) Dependency parsing
(d) Statistical machine translation
(e) Earley parsing
Choose the correct answer from the options given below
(a), (c), (d), (e) only
(b), (c), (d), (e) only
(a), (b), (c), (e) only
(a) and (b) only
Ans – (3)
Explanation – Parsing in Natural Language Processing (NLP) is a process, focusing and analyzing on the grammar structure of a sentence.
Top-down parsing – Like the name already indicates, it starts at the top. The start symbol is first broken down into less complex parts through the help of certain grammar rules.
Example is Recursive Descent Parsing.
Bottom-up parsing – This parsing method starts from the input tokens and builds up the parse tree using some grammar rules.
Example is Shift-Reduce Parsing.
Dependency Parsing – Focuses on relationships between words in a sentence (subject, object, and so much more). It is used for syntactical analysis.
Statistical Machine Translation – It is not a parsing technique and it is helpful in translation tasks.
Earley Parsing – A parsing technique based on dynamic programming useful for ambiguous grammars.
Q65 – In the content of Alpha Beta pruning in game trees which of the following statements are correct regarding cut off procedures?
(a) Alpha Beta pruning can eliminate subtrees with certainly when the value of a node exceeds both the alpha and beta bonds.
(b) The primarily purpose of Alpha-Beta pruning is to save computation time by searching fewer nodes in the same tree.
(c) Alpha Beta pruning guarantees the optimal solution in all cases by exploring the entire game tree.
(d) Alpha and Beta bonds are initialized to negative and positive infinity respectively at the root note.
(a), (c), (d) only
(b), (c), (d) only
(a), (b), (d) only
(c), (b) only
Ans – (3)
Explanation – Alpha-Beta pruning is, in short, an optimization technique of the Minimax algorithm in decision-making and game theory. It reduces the number of nodes that are evaluated, thus providing an efficient way to reach the same optimal move as in Minimax.
(a) If a node’s value goes beyond the current threshold of either alpha (α) or beta (β), it means that the subtree will not be further explored. This statement is true.
(b) Alpha-Beta pruning is capable of eliminating as many as half of the nodes that would be referred to the Minimax algorithm, thus improving efficiency considerably. Hence this statement is also true.
(c) Alpha-Beta pruning may not go through the complete game tree but passes only through the nodes that are important to get sufficient results. Therefore, this statement is false.
(d) α = -∞, which is the worst case for the maximizer
β = +∞, which is the worst case for the minimizer
So, option 3 is (a), (b) and (d).
Q66 –

Choose the correct answer from the options given below
(A)-(1), (B)-(II), (C)-(III), (D)-(IV)
(A)-(II), (B)-(I), (C)-(III), (D)-(IV)
(A)-(II), (B)-(I), (C)-(IV), (D)-(III)
(A)-(I), (B)-(II), (C)-(IV), (D)-(III)
Ans – (4)
Explanation – (A) ϕ ∩ {ϕ} match with (1) ϕ
- The intersection of the empty set ϕ with {ϕ} means finding common elements.
- Since ϕ has no elements, the result is also an empty set.
(B) {ϕ} ∩ {ϕ} match with (II) {ϕ}
- Both sets are {ϕ}, so their intersection is {ϕ}.
(C) {ϕ, {ϕ}} – ϕ match with (IV) {ϕ, {ϕ}}
- The difference between {ϕ, {ϕ}} and ϕ (empty set) means removing nothing, as ϕ has no elements.
(D) ϕ ∪ {{ϕ}} match with (III) {{ϕ}}
- The union of an empty set and {{ϕ}} results in {{ϕ}} because the empty set contributes nothing.
Q67 – Match List – I with List – II.
List – I
(A) SZA
(B) SKI
(C) SNA
(D) ISZ
List – II
(I) Increment M and skip it zero
(II) Skip if AC is negative
(III) Skip if input flag is on
(IV) Skip if AC is Zero
Choose the correct answer from the options given below:
(A)-(II), (B)-(IV), (C)-(I), (D)-(III)
(A)-(IV), (B)-(III), (C)-(II), (D)-(I)
(A)-(IV), (B)-(II), (C)-(I), (D)-(III)
(A)-(III), (B)-(IV), (C)-(II), (D)-(I)
Ans – (2)
Explanation – (A) SZA implies (IV) Skip if AC is Zero.
If the AC register has a value equal to 0, then the next instruction will be skipped. In case AC is not equal to zero, then the program will go down to mean execution.
(B) SKI implies (III) Skip if the Input Flag is set On.
Processor will skip the next instruction if the input flag is set (that is, an input device has data ready).
(C) SNA implies (II) Skip if the Accumulator (for AC) is Negative.
If the value contained in the AC register is negative, then skip the next instruction.
(D) ISZ implies (I) Increment Memory (M) And Skip If Zero.
This instruction increments the value stored in a memory location M. If after incrementing M becomes 0, the program skips the next instruction.
Q68 – Match List-1 with List-2
List – 1 | List – 2 |
(a) Bresenham | I. Hidden surface removal |
(b) Cohen – Sutherland | II. Line drawing algorithm |
(c) Sutherland – Hodgeman | III. Line clipping algorithm |
(d) Z-buffer | IV. Polygon clipping algorithm |
Choose the correct answer from the options given below
(a) | (b) | (c) | (d) | |
1. | III | II | IV | I |
2. | II | III | I | IV |
3. | II | III | IV | I |
4. | II | IV | III | I |
Ans – (3)
Explanation – (a) Bresenham’s Algorithm → (II) Line Drawing Algorithm
This is a technique for quickly rasterizing lines that fits the needs of integer calculations.
(b) Cohen-Sutherland Algorithm → (III) Line Clipping Algorithm
This is the technique for clipping lines that lie partially or completely outside a given rectangular boundary.
(c) Sutherland-Hodgeman Algorithm → (IV) Polygon Clipping Algorithm
A method to clip polygons against a rectangular clipping window.
(d) Z-buffer Algorithm → (I) Hidden Surface Removal
Used in 3D graphics to determine which surfaces are visible and which are hidden.
Q69 – Match List 1 with List 2
List 1 | List 2 |
(a) BCNF iff | I. Every JD is implied by the candidate key |
(b) 5NF iff | II. All underlying domains contain scalar values only |
(c) 1NF iff | III. Every MVD is implied by the candidate key |
(d) 4NF iff | IV. Every FD is implied by the candidate key |
Choose the correct answer from the options given below:
(a)-III, (b)-II, (c)-I, (d)-IV
(a)-IV, (b)-I, (c)-II, (d)-III
(a)-II, (b)-III, (c)-IV, (d)-I
(a)-IV, (b)-I, (c)-III, (d)-II
Ans – (2)
Explanation – BCNF (Boyce-Codd Normal Form)
A relation is in BCNF if each functional dependency (FD) is a functional determinant of the obtained candidate key.
5NF (Fifth Normal Form)
A relation is in 5NF if each join dependency (JD) is the result of the candidate key.
1NF (First Normal Form)
A relation is already in 1NF if all the elementary domains store (individual) scalar attributes only (nonscalar and nested ones are not allowed).
4NF (Fourth Normal Form)
A relation is in 4NF if any multivalued dependency (MVD) is a function of the candidate key.
Q70 – Match List-I with List-II
List-I | List-II |
(a) LRU | I. A page is written to secondary memory only when it has been selected for replacement. |
(b) Demand Paging | II. A page that has not been referenced for the longest time is replaced. |
(c) Long term scheduling | III. The decision to add to the number of processes that are partially or fully in main memory. |
(d) Medium term scheduling | IV. The decision to add to the pool of processes to be executed. |
Choose the correct answer from the options given below:
(a) | (b) | (c) | (d) | |
1. | I | III | IV | II |
2. | II | I | IV | III |
3. | III | II | I | IV |
4. | IV | II | III | I |
Ans – (2)
Explanation – (a) – II
LRU (Least Recently Used) – In this page replacement technique, the page which has not been used the longest gets replaced.
(b) – I
Demand Paging – Demand paging loads pages into memory only when needed. That is how a page is written to secondary memory. That is for pages that need replacement.
(c) – IV
Long Term Scheduling – Controls and monitors the admission of new processes into the system for execution.
(d) -III
Medium Term Scheduling – This refers to the scheduling of the number of processes present in the memory by swapping some processes out when memory is filled up.
Q71 – Match List-1 and List-2 according to input to the compiler phase that process it
List – 1 | List – 2 |
(a)Syntax tree | I. Code Generator |
(b)Intermediate Representation | II. Semantic Analyzer |
(c)Token Stream | III. Lexical Analyze |
(d)Character Stream | IV. Syntax Analyzer |
Choose the correct answer from the option given below:
(a)-IV, (b)-III, (c)-I, (d)-II
(a)-II, (b)-I, (c)-IV, (d)-III
(a)-II, (b)-IV, (c)-I, (d)-III
(a)-IV, (b)-I, (c)-II, (d)-III
Ans – (2)
Explanation – The compiler helps in the various stages of translating human-readable code into machine-executable code.
In the first stage, or (III) Lexical Analyzer takes a (d) character stream (raw source code) and translates it into generating tokens, which are units that have specific functions such as keywords, operators and identifiers.
The (IV) Syntax Analyzer analyses this (c) token stream and gives rise to the syntax tree while satisfying grammatical conditions.
Finally, the (II) Semantic Analyzer checks the (a) syntax tree for the presence of logical errors, like type mismatches or undeclared variables.
Once the syntax and semantics have been tested, an intermediate version of the code is generated by a program called the Intermediate Code Generator, this makes it easier for the compiler to optimize. The (I) Code Generator transforms the (b) intermediate representation into the final machine code, ensuring that the program is ready for execution.
Q72 – Match List-I with List-II
List-I(Propositions) | List-II(Disjunctive Normal Form (DNF)) |
(a) P Λ (P → Q) | I. P V Q |
(b) ¬(P V Q) → (P Λ Q) | II. (P Λ ¬P) V (P Λ Q) |
(c) P → Q | III. (¬P) V Q |
(d) P V (Q Λ R) | IV. (P Λ P) V (P Λ Q) V (P Λ R) V (Q Λ R) |
Choose the correct answer from the options given below
(a) | (b) | (c) | (d) | |
1. | I | II | III | IV |
2. | II | I | III | IV |
3. | III | I | II | IV |
4. | IV | III | II | I |
Ans – (2)
Explanation – (a) P Λ (P → Q)
=> P Λ (¬(P V Q))
=> (P Λ ¬P) V (P Λ Q) which is II.
(b) ¬(P V Q) → (P Λ Q)
=> ¬(¬(P V Q) V (P Λ Q))
=> ((P V Q) V ¬(P Λ Q))
=> ((P V Q) V (P V Q))
=> (P V Q), which is I.
(c) P → Q
=> ¬P V Q, which is III.
(d) P V (Q Λ R)
=> The single list-II option is IV. So, we will check the IV,
IV. (P Λ P) V (P Λ Q) V (P Λ R) V (Q Λ R)
=> P V (P Λ Q) V (P Λ R) V (Q Λ R) as [P Λ P = P]
=> P V (P Λ R) V (Q Λ R) as Absorption law
=> P V (Q Λ R) as Absorption law. Also, it is equal to (d).
Q73 – Match List – I with List – II.
List – I
(A) Greedy Best first search
(B) A*
(C) Recursive best first search
(D) SMA*
List – II
(I) The space complexity as O(d) where d = depth of the deepest optimal solution
(II) Incomplete even if the search space is finite
(III) Optimal if optimal solution is reachable otherwise return the best reachable optimal solution
(IV) Computation and space complexity is two light
Choose the correct answer from the options given below :
(A)-(II), (B)-(IV), (C)-(I), (D)-(III)
(A)-(II), (B)-(III), (C)-(I), (D)-(IV)
(A)-(III), (B)-(II), (C)-(IV), (D)-(I)
(A)-(III), (B)-(IV), (C)-(II), (D)-(I)
Ans – (1)
Explanation – Greedy Best First Search is an algorithm that selects the next step based only on how close it seems to the goal. While it is fast and does not make heavy memory demands, it is not always reliable due to its tendency to get caught up in misleading paths. This allows it to fit statement (II) because it is not guaranteed to be complete.
An A* is a more intelligent search because it looks at both the cost so far and an estimate of the distance that is left to the goal. An A* is likely to find the best path but needs a lot of memory and processing power. This fits statement (IV).
(Note: the word “two light” is a bit unusual, here it is meant to indicate the heavy resource usage of A* relative to the other algorithms.)
Recursive Best-First Search (RBFS) designs simplified memory requirements relative to A*. This approach needs the space of only the maximal depth of solutions (d) and uses space powerfully. It matches statement (I).
Simplified Memory-Bounded A* (SMA*) is yet another version of A* that works with bounded memory. The A* quality of approximation assures a good solution if there is sufficient memory; otherwise, the best possible solution with available resources will return. It matches statement (III).
Q74 – Match List-1 with List-2
List – 1 | List – 2 |
(a)Monoalphabetic Cipher | (I)Round Key |
(b)DES | (II)One-to-many relationship |
(c)Stream Cipher | (III)One-to-one relationship |
(d)Polyalphabetic Cipher | (IV)Feedback mechanism |
Choose the correct answer from the options given below:
(a)-III, (b)-I, (c)-IV, (d)-II
(a)-III, (b)-IV, (c)-II, (d)-I
(a)-I, (b)-III, (c)-IV, (d)-II
(a)-II, (b)-I, (c)-IV, (d)-III
Ans – (1)
Explanation – A monoalphabetic cipher is the type of encryption where the ciphertext letter corresponding to each letter of the plaintext has always been a fixed letter, therefore, a one-to-one relationship between original and encrypted letters exists.
Data Encryption Standard (DES) is the popular encryption algorithm applied in many stages or rounds in order to encrypt data. With each round a different round key is applied derived from the principal key.
In a stream cipher, the information is encrypted bit by bit or byte per byte instead of processing it in blocks. Most use the feedback mechanism, that is, past encrypted bits are used to determine future encryption.
A polyalphabetic cipher changes the substitution pattern throughout the message, meaning that the same letter in plaintext can be replaced with different letters in ciphertext at different positions. Therefore, this creates a one-to-many relationship, and it is much safer than a monoalphabetic cipher.
Q75 – Match List-I with List-II
List-I | List-II |
(a) Hill Climbing | I. O(b^d) |
(b) Best first search | II. O(bd) |
(c) A* Search | III. O(1) |
(d) Depth first Search | IV. O(b^m) |
Choose the correct answer from the options given below:
(a) | (b) | (c) | (d) | |
1. | III | I | IV | II |
2. | II | I | IV | III |
3. | II | IV | I | III |
4. | I | III | II | IV |
Ans – (1)
Explanation – Hill Climbing is a heuristic approach that moves towards the best neighbour at each step. So, its time complexity is O(1).
Best First Search (BFS) is a graph search algorithm that selects the promising node first according to a heuristic. BFS expands those nodes that have the best (lowest) heuristic value, using a priority queue in the process.
The time complexity is heavily dependent on the branching factor (b) and depth (d). In the worst-case scenario, the complexity is O(b^d), meaning it can become exponentially increasing with more alternatives.
The A* search is an informed search algorithm that takes the best of both uniform cost search and greedy best-first search methods to find the shortest path. The time complexity of A* search, in the worst case, is given by O(b^m), where b is the branching factor (the average number of possible child nodes per tree node) and m is the maximum depth of the search tree. For example, if the heuristic function is poor or misleadingly informative, A* may expand cells, for instance, two or three steps below the actual solution, leading to exponential growth in the number of expanded cells with respect to m, rather than stopping at the depth d of the optimal solution.
Depth First Search (DFS) explores as deep as possible before backtracking. So, the time complexity is O(bd) where b is the branching factor and d is depth.
Q76 – Arrange the following in ascending order
(a) Remainder of 4916 when divided by 17
(b) Remainder of 2446 when divided by 9
(c) Remainder of 15517 when divided by 17
(d) Last digit of the number 745
Choose the correct answer from the options given below
(a), (b), (c), (d)
(a), (b), (d), (c)
(a), (c), (b), (d)
(d), (c), (b), (a)
Ans – (3)
Explanation – (a): 4916 = (51 – 2)16
Since 51 is divisible by 17, its remainder when divided by 17 will be (-2)16
(-2)16 = (-2)4*4 = (16)4 = (17 – 1)4
Since 17 is divisible by 17, its remainder when divided by 17 will be (-1)4 = 1
(b): 2446
21 = 2 mod 9 = 2
22 = 4 mod 9 = 4
23 = 8 mod 9 = 8
24 = 16 mod 9 = 7
25 = 32 mod 9 = 5
26 = 64 mod 9 = 1
We can see that 2n mod 9 repeats every 6 terms, 2, 4, 8, 7, 5, 1
You can check 27 = 128 mod 9 = 2
So, the cycle repeats every 6 terms, then we can reduce 446 mod 6. So, 446 mod 6 = 2.
In the cycle of 2, 4, 8, 7, 5, 1, the 2nd term which is 4 is our remainder.
(c): 15517 = (153 + 2)17
Since 153 is divisible by 17, its remainder when divided by 17 will be 217 = 2*216
216 = 24*4 = 164 = (17 – 1)4
Since 17 is divisible by 17, its remainder when divided by 17 will be (-1)4 = 1
Then the overall remainder is 2*216 = 2*1 = 2
(d): 745
71 = 7
72 = 49
73 = 343
74 = 2401
So, the last digit repeats every 4 terms. 7, 9, 3, 1
We can reduce 45 by 45 mod 4 = 1
In the cycle of 7, 9, 3, 1, the 1st term which is 7 is our remainder.
By sorting the options in ascending order remainders, we get option 3. (a), (c), (b), (d)
Q77 – In most general case, the computer needs to process each instruction with the following sequence of steps:
(A) Calculate the effective address
(B) Execute the instruction
(C) Fetch the instruction from memory
(D) Fetch the operand from memory
(E) Decode the instruction
Choose the correct answer from the options given below:
(A), (B), (C), (D), (E)
(A), (B), (C), (E), (D)
(C), (E), (A), (D), (B)
(C), (E), (D), (A), (B)
Ans – (3)
Explanation – Considering the most general case, the proper order of steps for processing an instruction is as follows –
(C) Fetch the instruction from memory – Instruction is brought from memory.
(E) Decode the instruction – Determine the meaning of the instruction that needs to perform an operation.
(A) Calculate the effective address – The effective address is calculated if the instruction requires memory access.
(D) Fetch the operand from memory – The operand is brought from memory (again, if needed).
(B) Execute the instruction – The CPU executes the operation dictated by that instruction.
Hence the right choice is option 3.
Q78 – Consider the following code segment
int arr[] = {0, 1, 2, 3, 4};
int i = 1, *ptr;
ptr = arr + 2;
Arrange the following printf statements in the increasing order of their output.
(a) printf(“%d”, ptr[i]);
(b) printf(“%d”, ptr[i+1]);
(c) printf(“%d”, ptr[-i]);
(d) printf(“%d”, ptr[-i+1]);
Choose the correct answer from the options given below
(c), (a), (b), (d)
(c), (d), (a), (b)
(d), (a), (b), (c)
(a), (b), (d), (c)
Ans – (2)
Explanation – (a) print ptr[i], it means *(ptr + i)
Now, ptr = 2 and i = 1, So, arr[3] = 3
(b) print ptr[i+1], it means *(ptr + i + 1)
Now, ptr = 2 and i = 1, So, arr[4] = 4
(c) print ptr[-i], it means *(ptr – i)
Now, ptr = 2 and i = 1, So, arr[1] = 1
(d) print ptr[-i + 1], it means *(ptr – i + 1)
Now, ptr = 2 and i = 1, So, arr[2] = 2
Option 2 is the correct, because (c), (d), (a), (b) is in the increasing order.
Q79 – The steps for analysis and design of object oriented system.
(A) Draw interaction diagrams
(B) Draw state chart and object diagram
(C) Draw use case and activity diagram
(D) Draw component and deployment diagram
(E) Draw class diagram
Choose the correct answer from the options given below :
(E)→(B)→(A)→(C)→(D)
(B)→(A)→(E)→(D)→(C)
(E)→(C)→(B)→(D)→(A)
(C)→(A)→(E)→(B)→(D)
Ans – (4)
Explanation – (C) Draw use case and activity diagram
The first step is talking about how requirements of the system are secured and how users will interact with the system.
Use case diagrams describe what functionalities a system should provide to different actors within a particular scope.
Activity diagrams describe the flow of activities to be executed.
(A) Draw interaction diagrams
Now that use cases have been defined, interaction diagrams (sequence and collaboration diagrams) will be developed to gain insight into how objects interact under varying scenarios.
(E) Draw class diagram
Following the definition of interactions comes the identification of objects and the relations to one another, thus leading into the class diagram, the backbone of object-oriented design.
(B) Draw state chart and object diagram
State chart diagrams describe how states are transformed by the internal objects whereas the object diagrams describe the object instances with respect to some scenario.
(D) Draw component and deployment diagram
Finally, this is where the focus is on the implementation, the drawing-up of component diagrams (software components) and deployment diagrams (physical system architecture).
Q80 – Arrange the following levels of interrupt protection within the Linux Kernel, in the order of increasing priority.
(a) user mode programs
(b) bottom half interrupt handlers
(c) Kernel system service routines
(d) top half interrupt handlers
Choose the correct answer from the options given below:
(a), (b), (d), (c)
(a), (c), (b), (d)
(a), (c), (d), (b)
(d), (a), (c), (b)
Ans – (2)
Explanation – At each level, there exists a different level of interrupt protection in the Linux kernel, and they proceed according to a priority order: the order of increasing priority implies that operations of lower priority are processed first, while higher priority operations are processed last. Let’s analyze each in turn.
(a) User Mode Programs – These run in user space and are at the lowest priority. They can always get pre-empted by kernel operations and interrupts.
(c) Kernel System Service Routines – Those run in kernel mode when system calls are being executed. They have a higher priority than user mode programs but can still get interrupted by hardware interrupts.
(b) Bottom Half Interrupt Handlers – These listen for deferred work enumerated by the top half of an interrupt. They are of higher priority than system service routines but can still be interrupted by top-half handlers.
(d) Top Half Interrupt Handlers – These are the highest priority because these execute immediately on hardware interrupts response. They run with interrupts disabled to ensure their swift execution.
Q81 – Arrange the following phases of a compiler as per their order of execution (start to end)
(a) Target code generation
(b) Syntax Analysis
(c) Code optimization
(d) Semantic Analysis
(e) Lexical Analysis
Choose the correct answer from the options given below
(b), (e), (d), (a), (c)
(e), (d), (b), (a), (c)
(e), (b), (d), (c), (a)
(b), (d), (e), (a), (c)
Ans – (3)
Explanation – Phases of a Compiler (In Correct Order of Execution)
A compiler translates source code into machine code through many phases. The following is the correct order of execution of these phases
(e) Lexical Analysis – This is the first phase; the source code is broken into tokens.
(b) Syntax Analysis (Parsing) – This is done to see whether the tokens conform to certain grammar rules.
(d) Semantic analysis – This is done, checking if statements make sense logically.
(c) Code Optimization – The intermediate code is optimized for better performance.
(a) Target Code Generation – Is producing the final machine code.
Q82 – The prototyping model has the sequence:
(a) Customer Evaluation
(b) Quick Design
(c) Requirements
(d) Implement
(e) Design
Choose the correct answer from the options given below:
(c) -> (a) -> (d) -> (b) -> (e)
(b) -> (c) -> (a) -> (d) -> (e)
(c) -> (b) -> (d) -> (a) -> (e)
(e) -> (b) -> (c) -> (d) -> (a)
Ans – (3)
Explanation – The Prototyping Model is iterative, and the prototype is built, tested, and later refined through user feedback before the final system is developed.
1. Take down requirements from customers.
2. Create a quick design (prototype) based on early requirements.
3. Implement a prototype and show it to the customer for evaluation.
4. The customer evaluates the prototype and provides feedback.
5. This feedback is used to modify the final design before the actual development starts.
Thus, the correct answer is option 3.
Q83 – Arrange the following encoding strategies used in Genetic Algorithms (GAs) in the correct sequence starting from the initial step and ending with the final representation of solution:
(a) Binary Encoding
(b) Real valued Encoding
(c) Permutation Encoding
(d) Gray coding
Choose the correct answer from the options given below:
(d), (b), (a), (c)
(b), (d), (a), (c)
(c), (d), (a), (b)
(b), (c), (a), (d)
Ans – (3)
Explanation – In GAs, we must encode the solutions in some way understandable to the computer.
(c) Permutation Encoding
This is just like making a list.
Example – For Traveling Salesman Problem, if we know the order in which we will be visiting the cities, we can simply list them.
(d) Gray Code
Gray codes are used to minimize the risk of errors caused by changes occurring between adjacent numbers.
Gray coding changes only one bit at any given time when representing a number.
Example – Binary 1100 → Gray Code 1010
(a) Binary Encoding
Binary refers to the process of converting information into 0s and 1s (since computers understand binary).
Most commonly used by genetic algorithms.
(b) Real-Valued Encoding
Converts binary back into real values for final output.
Useful when, in problems, decimal values are required as solutions.
Q84 – Arrange the following steps in the correct order for a DHCP Client to renew its IP lease with a DHCP server:
(a) DHCP client sends a DHCPREQUEST message
(b) DHCP server acknowledges the renewal with a DHCPACK message
(c) DHCP client checks the local lease timer and initiates renewal
(d) DHCP server updates its lease database
Choose the correct answer from the options given below:
(a), (b), (c), (d)
(c), (d), (b), (a)
(c), (b), (a), (d)
(c), (a), (b), (d)
Ans – (4)
Explanation – DHCP (Dynamic Host Configuration Protocol) is a network protocol that enables the automatic assignment of an IP address, subnet mask, gateway, and DNS servers to a device on the network. This protocol eliminates the need to configure each device manually.
DHCP Server – Assigns a dynamic IP address to a client.
DHCP Client – A device requesting an IP address, e.g., a computer and/or a phone.
DHCP Lease – An assignment of a temporary IP address, which has a duration.
DHCP Messages – Consist of DHCPDISCOVER, DHCPOFFER, DHCPREQUEST, and DHCPACK in leasing of IP addresses.
The question is to how the client should request the renewal of its lease with a DHCP server just before the lease has expired.
A DHCP lease is bound for a certain amount of time and needs to be renewed. The client must send a request for lease renewal, acknowledged by the server.
Here is the answer –
(c) The client checks on its lease timer to see if it is time to additionally renew its lease.
(a) The client sends a DHCPREQUEST message to the server requesting a lease renewal.
(b) The server responds with a DHCPACK message acknowledging this lease renewal.
(d) The server then updates its lease database to reflect the renewed lease.
Q85 – Arrange the following steps in the correct sequence for applying an unsupervised learning technique such as K-means clustering is to a data set:
(a) Randomly initialise cluster centroids.
(b) Assign each data point to nearest cluster centroid.
(c) Update the cluster centroids based on the mean of data points assigned to each cluster.
(d) Specify the number of clusters (K) to partition the data into
(e) Repeat steps B and C until convergence criteria are met.
Choose the correct answer from the options given below:
(d), (a), (b), (c), (e)
(a), (b), (c), (d), (e)
(c), (b), (a), (d), (e)
(d), (c), (a), (b), (e)
Ans – (1)
Explanation – (d) Specify the number of clusters (K) to partition the data into – Decide how many groups you want, in other words, choose a number K, which is the number of clusters.
(a) Randomly initialise cluster centroids – Decide on initial locations for each of the K clusters. Randomly choose K points to serve as the initial centres of clusters.
(b) Assign each data point to nearest cluster centroid – Assign each of the collected data points into a cluster. For each collected data point, determine the closest centre, thus the data point gets assigned to that cluster.
(c) Update the cluster centroids based on the mean of data points assigned to each cluster – Calculate the new centre for each of the clusters. For each cluster, the new centre is the average of all data points assigned to that cluster.
(e) Repeat steps B and C until convergence criteria are met –
Repeat Assignment and Update. Continue reassigning points and recalculate centres until the groups stay constant or cease to change effectively.
So, option 1 is the answer.
Q86 – Given below are two statements:
Statement I – If H is non empty finite subset of a group G and ab ϵ H ꓯ a, b ϵ H, then H is also a group.
Statement II – There is no homomorphism exist from (Z, +) to (Q, +); where Z is set of integers and Q is set of rational number.
In the light of the above statements, choose the most appropriate answer from the options given below:
Both Statement I and Statement II are correct.
Both Statement I and Statement II are incorrect.
Statement I is correct, but Statement II is incorrect.
Statement I is incorrect, but Statement II is correct.
Ans – (3)
Explanation – Statement I discusses subgroups in the theory of groups.
A group is defined as a set that possesses a binary operation-and-satisfies four properties
Closure – If a and b belong to the group, then ab is also a member of the group.
Identity – There exists an element e such that ae = ea = a for all a.
Inverse – For every a, there exists an a−1 such that aa−1=e.
Associativity – (ab)c = a(bc).
Now, if H is a nonempty finite subset of G, the condition states that multiplying any two elements from H results in still another member of H. This condition is, hence, called closure. So, statement I is true.
Statement II is about some homomorphisms between two mathematical structures.
A homomorphism is a function respecting the group operation. If f: (Z,+) → (Q,+) is a homomorphism, then it must satisfy
f(a+b) = f(a) + f(b) ∀a,b ∈ Z.
The question itself says no such function exists. Thus, there is no possible mapping of the integers into the rational numbers that preserves addition. But this is false, for a simple homomorphism is f(n)=n. Hence Statement II is false.
Q87 – Given below are two statements:
Statement I – The friend function and the member functions of a friend class directly access the private and protected data.
Statement II – The friend function can access the private data through the member functions of the base class.
In the light of the above statements, choose the most appropriate answer from the options given below:
Both Statement I and Statement II are correct.
Both Statement I and Statement II are incorrect.
Statement I is correct but Statement II is incorrect.
Statement I is incorrect but Statement II is correct.
Ans – (1)
Explanation – A friend function is one which is allowed to access private and protected members of a particular class directly. In the same way, a friend class is a class to which access is granted to its member functions which in turn can manipulate the private and protected members of another class. So, Statement I is correct.
Though a friend function does not directly become a friend of the base class, it can still invoke public or perhaps protected member functions of that base class.
Being the members of the base class, they are allowed to directly access the base class private data.
So, the friend function gets a backdoor into that private data through a protected member function of the base class. So, Statement II is correct.
Q88 – Given below are two statements:
Statement (I): A thread is a dispatchable unit of work that does not executes sequentially and is not interruptible
Statement (II): It is not possible to alter the behaviour of a thread by altering its context when thread is suspended
In the light of the above statements, choose the most appropriate answer from the options given below:
Both Statement I and Statement II are correct
Both Statement I and Statement II are incorrect
Statement I is correct but Statement II is incorrect
Statement I is incorrect but Statement II is correct
Ans – (2)
Explanation – A thread is a unit of work that is lightweight, allowing it to be dispatched by the operating system for actual execution purposes. Threads follow a strict sequence of instructions just like processes, allowing them to be executed in a strictly sequential manner. The other aspect that is contradictory to the statement is that threads are interruptible. The operating system may suspend, resume, pre-empt, or even kill them.
In a similar manner, the second statement is also incorrect. On suspension, its execution is interrupted, but its context-such as register values, program counter, and stack-is preserved by the operating system. The context can also be modified, making it possible for the execution behavior of the thread to change when it starts executing again. This means that it is possible to modify the context of the thread when it is suspended in order to modify its behavior. Since both are incorrect, the correct option is Option 2.
Q89 – Given below are two statements:
Statement I: In Reuse Oriented Model, Modification of the old system parts appropriate to the new requirements.
Statement II: In Reuse Oriented Model, Integration of the modified parts are not possible into the new systems.
In the light of the above statements, choose the most appropriate answer from the options given below:
Both Statement I and Statement II are correct.
Both Statement I and Statement II are incorrect.
Statement I is correct but Statement II is incorrect.
Statement I is incorrect but Statement II is correct.
Ans – (3)
Explanation – Statement I is correct. In the Reuse-Oriented Model, existing system components (or software modules) are altered to fit new requirements. This, therefore, shortens the time and costs of development.
Statement II is Incorrect. The Reuse-Oriented Model provides a way to integrate modified parts into the new system. In fact, integration is a crucial step of this model to ensure that the reused components interact within the new system.
Thus, the correct choice is option 3.
Q90 – Given below are two statements:
Statement I: In datagram networks – routers hold state information about correction.
Statement II: In virtual circuit network – each virtual circuit requires router table space per connection.
In the light of the above statements, choose the most appropriate answer from the options given below:
Both Statement I and Statement II are correct.
Both Statement I and Statement II are incorrect.
Statement I is correct but Statement II is incorrect.
Statement I is incorrect but Statement II is correct.
Ans – (4)
Explanation – Each router in datagram networks, example, in IP across the Internet, does not maintain a state information of connections.
In datagram networks, each packet is treated on its own or independently, and a router will then base its forwarding decision on a destination address from the packet itself.
Since routers have information concerning the state of connections, then, statement I is not correct.
In a virtual circuit network (such as ATM or MPLS), connections are established before communication starts while routers have a routing table entry for each virtual circuit.
Which implies, every active connection needs to take its space in the routing table of the router for storing virtual circuit information. Statement II becomes correct.
Question Number: 91-95
Question Label: Comprehension
Food X contains 6 units of Vitamin D per gram and 7 units of Vitamin E per gram and cost is Rs 12 per gram.
Food Y contains 8 units of vitamin D per gram and 12 units of Vitamin E per gram and cost is Rs 20 per gram.
The daily minimum requirements of vitamin D and E are 100 units and 120 units respectively.
Suppose x is quantity (in gram) of food X, y is quantity (in gram) of food Y. Answering the following question based on the above paragraph given.
Q91 – The minimum cost of food is :
205
250
330
200
Ans – (1)
Explanation – Food X contains
Vitamin D per gram = 6 units
Vitamin E per gram = 7 units
Cost = Rs 12 per gram
Food Y contains
Vitamin D per gram = 8 units
Vitamin E per gram = 12 units
Cost = Rs 20 per gram
Daily minimum requirement is
Vitamin D >= 100
Vitamin E >= 120
For vitamin D, 6x + 8y >= 100 … (i)
For vitamin E, 7x + 12y >= 120 …(ii)
Cost minimize is, C = 12x + 20y
From (i) and (ii), we get x = 15, y = 5/4
So, to minimize cost C = 12(15) + 20(5/4) = 205
So, the answer is option 1.
Q92 – Which of the following are quantities (in grams) of food X and Y respectively when the cost of food is minimum:
0 and 12 ½
15 and 5/4
120/7 and 0
0 and 10
Ans – (2)
Explanation – We get in question number 91, x = 15 and y = 5/4
So, the option 2 is the answer.
Q93 – Which of the following constrains when formulating the LPP ?
6x + 7y <= 100, 8x + 12y <= 120, x, y >= 0
6x + 8y <= 100, 7x + 12y <= 120, x, y >= 0
6x + 7y >= 100, 8x + 12y >= 120, x, y >= 0
6x + 8y >= 100, 7x + 12y >= 120, x, y >= 0
Ans – (4)
Explanation – We get in question number 91,
For vitamin D, 6x + 8y >= 100 … (i)
For vitamin E, 7x + 12y >= 120 …(ii)
So, the option 4 is the answer.
Q94 – The dual of the formulated LPP is:
1. | Max Z = 100u + 120vs.t.6u + 7v ≤ 128u + 12v ≤ 20u, v ≥ 0 |
2. | Max Z = 12u + 20vs.t.6u + 7v ≤ 1008u + 12v ≤ 120u, v ≥ 0 |
3. | Max Z = 100u + 120vs.t.6u + 7v ≤ 128u + 7v ≤ 20u, v are unrestricted |
4. | Max Z = 100u + 120us.t.6u + 7v ≥ 128u + 12v ≥ 20u, v ≥ 0 |
Ans – (1)
Explanation – We get in question number 91,
For vitamin D, 6x + 8y >= 100 … (i)
For vitamin E, 7x + 12y >= 120 …(ii)
Cost minimize is, C = 12x + 20y
The dual of the formulated LPP is
Max Z = 100u + 120v
s.t.
6u + 7v ≤ 12
8u + 12v ≤ 20
u, v ≥ 0
Q95 – Which of the following constrains when formulating the LPP?
6x + 7y <= 100, 8x + 12y <= 120, x, y >= 0
6x + 8y <= 100, 7x + 12y <= 120, x, y >= 0
6x + 7y >= 100, 8x + 12y >= 120, x, y >= 0
6x + 8y >= 100, 7x + 12y >= 120, x, y >= 0
Ans – (4)
Explanation – We get in question number 91,
For vitamin D, 6x + 8y >= 100 … (i)
For vitamin E, 7x + 12y >= 120 …(ii)
Also, x, y ≥ 0
Cost minimize is, C = 12x + 20y
Question Number: 96-100
Question Label: Comprehension
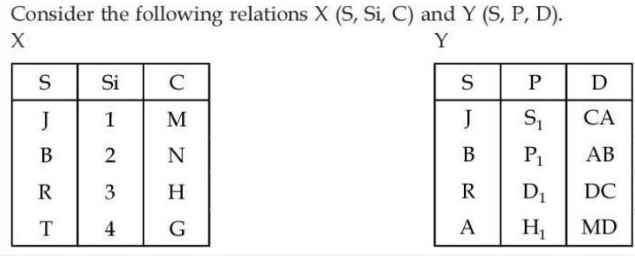
Q96 – Number of tuples by applying right outer join on relation X and Y is/are:
16
5
3
4
Ans – (3)
Explanation – Right outer join means all tuples from right table and matching tuples from left table.
S | Si | C | P | D |
J | 1 | M | S1 | CA |
B | 2 | N | P1 | AB |
R | 3 | H | D1 | DC |
A | Null | Null | H1 | MD |
There are 4 tuples in the result.
Q97 –
![]()
1
3
4
6
Ans – (3)
Explanation – The Left Outer Join is denoted by a left semi-circle symbol with a join sign (⟕).
Definition of Left Outer Join
A Left Outer Join collects all tuples from a first relation called “left” (X) and looks for correspondence in the second relation called “right” (Y) based on some common attribute S. If no matching tuple appears in Y, the missing field values receive NULL values.
- Join X and Y on common attribute S.
- Keep all tuples from the left.
- Fill P and D with NULLs in case Y does not match.
- J, B and R are in both relations, hence joining their preserved values.
- T is in X but not in Y, hence NULL in P, D as per the condition specified.
The final result contains 4 tuples and the answer is option 3.
Q98 – Which of the following join is used to get all the tuples of relation X and Y with Null values of corresponding missing values?
Left outer join
Right outer join
Natural join
Full outer join
Ans – (4)
Explanation – A full outer join (⟗) thus returns all matching tuples from both relations X and Y and if there is no matching tuple, NULL values are placed in any tuples for the attributes missing information.
Q99 – Number of tuples obtained by applying cartesian product over X and Y are:
16
12
04
32
Ans – (1)
Explanation – The number of tuples obtained by applying cartesian product over X and Y are –
X has 4 tuples and Y also has 4 tuples, so total tuples = 4 x 4 = 16 which is option 1.
Q100 –
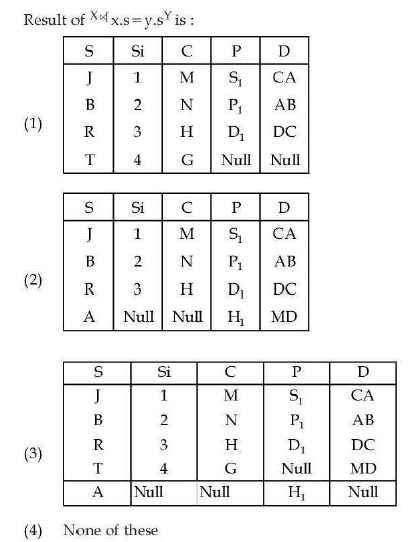
Ans – (2)
Explanation – A right outer join will return
- All tuples from the right relation (Y).
- Matching tuples from the left relation (X).
- If there is no match, NULL values are placed for missing attributes from X.
Apply the right outer join (X ⟖ Y)
The join condition is based on the S attribute (common key).
A right outer join guarantees that all tuples in Y will be in the result, even if they do not match with the left relation explicitly.
If a tuple in Y does not have a matching value in the left relation X, the missing columns from X will be placed with NULL values.
Hence the option will be 2.